
从一个业务场景聊聊 ZooKeeper 队列使用
背景描述
目前在做的 APP 客户端有个业务场景,对于登录的新用户需要做一些操作,例如初始化用户账户信息,给该新用户发放一些优惠,比如发放优惠券、赠送经验积分等等。对于这种场景一般很容易想到使用消息队列(MQ),但是考虑到目前的业务场景,每天新增的用户并不多,如果引入专门的消息队列框架(例如:RocketMQ、RabbitMQ)等感觉比较重,意义并不是很大。
PS. 一句话需求,新增登录用户模块要实现功能解耦,用户登录与新用户业务逻辑功能分开,想到使用消息队列机制,但是不想引入重量级 MQ 框架。
通过调研,发现利用 ZooKeeper + Curator 是可以实现分布式队列类似的效果的,同时预研使用 ZooKeepr + Curator 实现了该功能,这一篇文章对 ZooKeepr + Curator 实现队列机制的一个总结。
ZooKeeper 队列实现原理
生产者
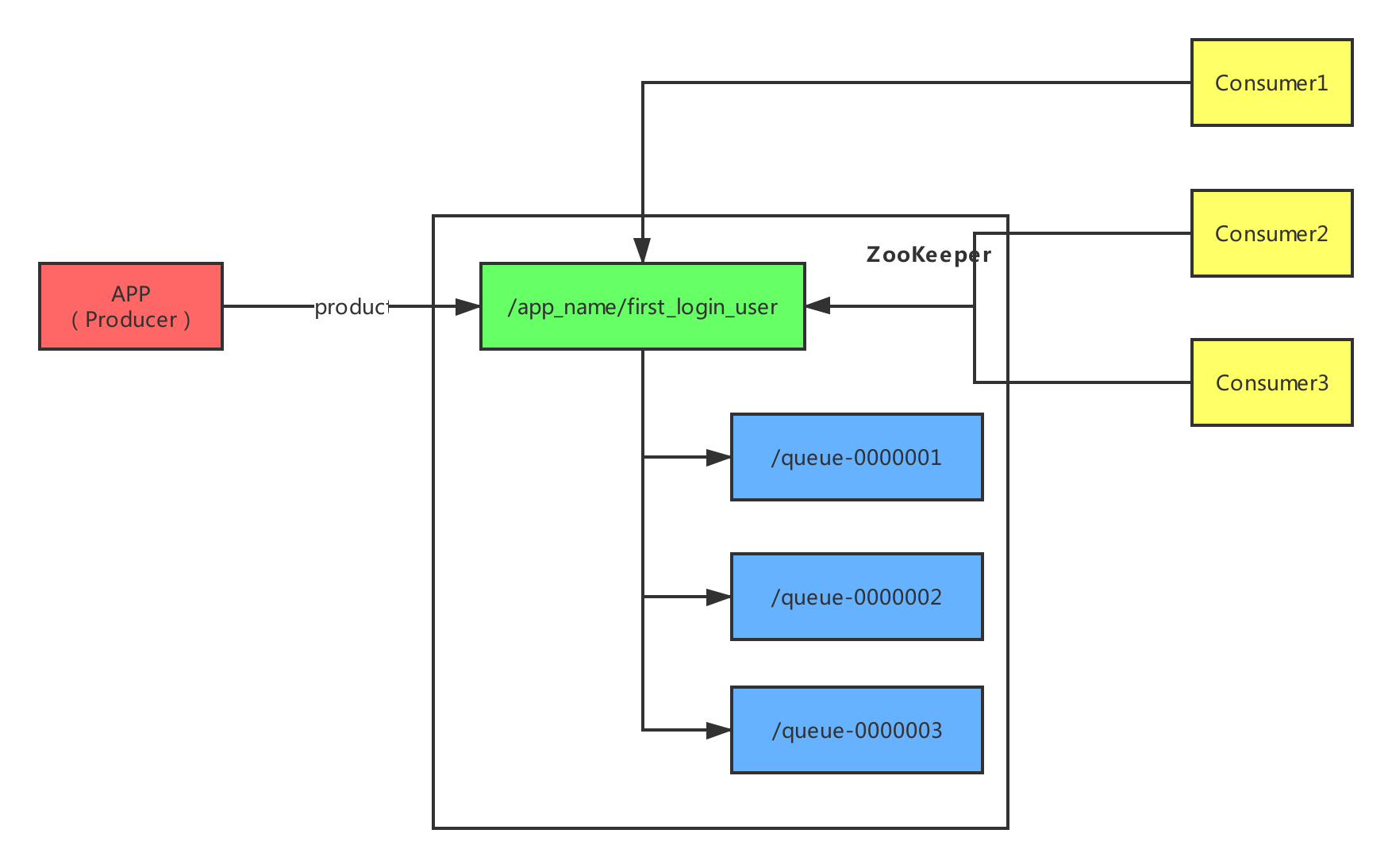
为了在 ZooKeeper 中实现分布式队列,需要设计一个 ZNode 节点来存放数据,这个节点是队列节点,例如:/app_name/first_login_user。生产者向队列中存放数据,每一个消息数据都是队列节点下的一个新节点,我们称作消息节点。消息节点的命名规则为:queue-xxxx,其中 xxxx 是一个单调递增序列,从 ZooKeeper 内部存储结构来说,其实就是创建持久顺序(PERSISTENT_SEQUENTIAL)类型节点来实现。这样,生产者不断的在队列节点下创建消息节点,消息节点数据存储为:queue-xxxx,这就是生产者端的实现原理。
消费者
消费者从队列中获取数据是通过 getChildren() 方法获取到队列节点中的所有消息节点,然后获取消息节点中存储数据,处理业务逻辑,并删除消息节点。 如果 getChildren() 没有获取到节点数据,说明队列是空的,则消费者进入等待状态,同时调用 getChildren() 方法设置观察者监听队列节点,队列节点发生变化后(消息节点变更),触发监听事件,唤起消费者。
Curator 框架队列实现
DistributedQueue
Distributed Queue - An implementation of the Distributed Queue ZK recipe. Items put into the queue are guaranteed to be ordered (by means of ZK’s PERSISTENTSEQUENTIAL node). If a single consumer takes items out of the queue, they will be ordered FIFO. If ordering is important, use a LeaderSelector to nominate a single consumer.
Distributed Queue - ZK 的 分布式队列实现。添加到队列中的元素是可以保证顺序性的(通过 ZK 的 PERSISTENT SEQUENTIAL 节点类型实现)。如果只有单一消费者从队列中获取元素,可以保证以 FIFO 顺序消费元素。如果顺序性是非常重要的,可以通过 LeaderSelector 方式只选举出一个消费者。
数据存储格式:
1 | queue-0000000001 |
使用方式:
1 | // 核心类 |
DistributedIdQueue
Distributed Id Queue - A version of DistributedQueue that allows IDs to be associated with queue items. Items can then be removed from the queue if needed.
Distributed Id Queue - 允许 ID 与队列元素关联的 DistributedQueue 版本实现。如果有需要可以根据 ID 删除元素。
数据存储格式:
1 | queue-|id-1|0000000001 |
使用方式:
1 | // 核心类 |
DistributedPriorityQueue
Distributed Priority Queue - An implementation of the Distributed Priority Queue ZK recipe.
Distributed Priority Queue - 分布式优先级队列的 ZK 实现。
数据存储格式:
1 | queue-10000001F0000000001 |
使用方式:
1 | // 核心类 |
DistributedDelayQueue
Distributed Delay Queue - An implementation of a Distributed Delay Queue.
Distributed Delay Queue - 分布式延迟队列实现。
数据存储格式:
1 | queue-|16DE33C4F8D|0000000001 |
使用方式:
1 | // 核心类 |
SimpleDistributedQueue
Simple Distributed Queue - A drop-in replacement for the DistributedQueue that comes with the ZK distribution.
1 | // 核心类 |
系统实现
业务系统中是采用 DistributedQueue 的实现,首先在用户登录成功后向 ZooKeeper 的固定节点下写入 PERSISTENT_SEQUENTIAL 数据,写入后直接返回,不阻塞用户登录操作;在另外的线程中消费 DistributedQueue 队列中数据,直接按顺序获取节点数据,开始进行业务逻辑处理。
写在最后
对于使用 ZooKeeper 实现的分布式消息队列,需要注意一些问题。首先,对于使用 ZooKeeper 实现的队列这件事情本身,Curator 的官方文档就是不推荐的:
IMPORTANT - We recommend that you do NOT use ZooKeeper for Queues. Please see Tech Note 4 for details.
ZooKeeper 的使用手册页面列举了一些 ZooKeeper 作为队列的使用场景。Curator 包括了几种队列的实现方式,以我们的经验,使用 ZooKeeper 作为消息队列是一个糟糕的选择:
- ZooKeeper 有 1MB 的传输限制。 实践中 ZNode 必须相对较小,而队列包含成千上万的消息,可能非常的大;
- 如果有很多节点,ZooKeeper 启动时相当的慢。而使用队列需要创建很多 ZNode 节点,所以在使用中需要显著调大 initLimit 和 syncLimit 参数值;
- 当某个 ZNode 很大的时候会很难清理,同时调用这个节点的
getChildren()方法会失败; - 当出现大量的包含成千上万的子节点的 ZNode 时,ZooKeeper 的性能会急剧下降;
- ZooKeeper 的数据完全存放在内存中,如果有大量的队列消息会占用很多的内存空间。
虽然从官方文档上来看,并不推荐使用 ZooKeeper 作为消息队列载体,但这是在大量消息的队列使用场景下,对于小规模的队列场景,例如我们新登录用户场景,一天也就几百个消息,其实也是没有问题的,之所谓一切脱离业务谈技术架构都是耍流氓。