// Packing and unpacking ctl // 5. `runStateOf()`,获取线程池状态,通过按位与操作,低29位将全部变成0 privatestaticintrunStateOf(int c) { return c & ~CAPACITY; } // 6. `workerCountOf()`,获取线程池worker数量,通过按位与操作,高3位将全部变成0 privatestaticintworkerCountOf(int c) { return c & CAPACITY; } // 7. `ctlOf()`,根据线程池状态和线程池worker数量,生成ctl值 privatestaticintctlOf(int rs, int wc) { return rs | wc; }
/* * Bit field accessors that don't require unpacking ctl. * These depend on the bit layout and on workerCount being never negative. */ // 8. `runStateLessThan()`,线程池状态小于xx privatestaticbooleanrunStateLessThan(int c, int s) { return c < s; } // 9. `runStateAtLeast()`,线程池状态大于等于xx privatestaticbooleanrunStateAtLeast(int c, int s) { return c >= s; }
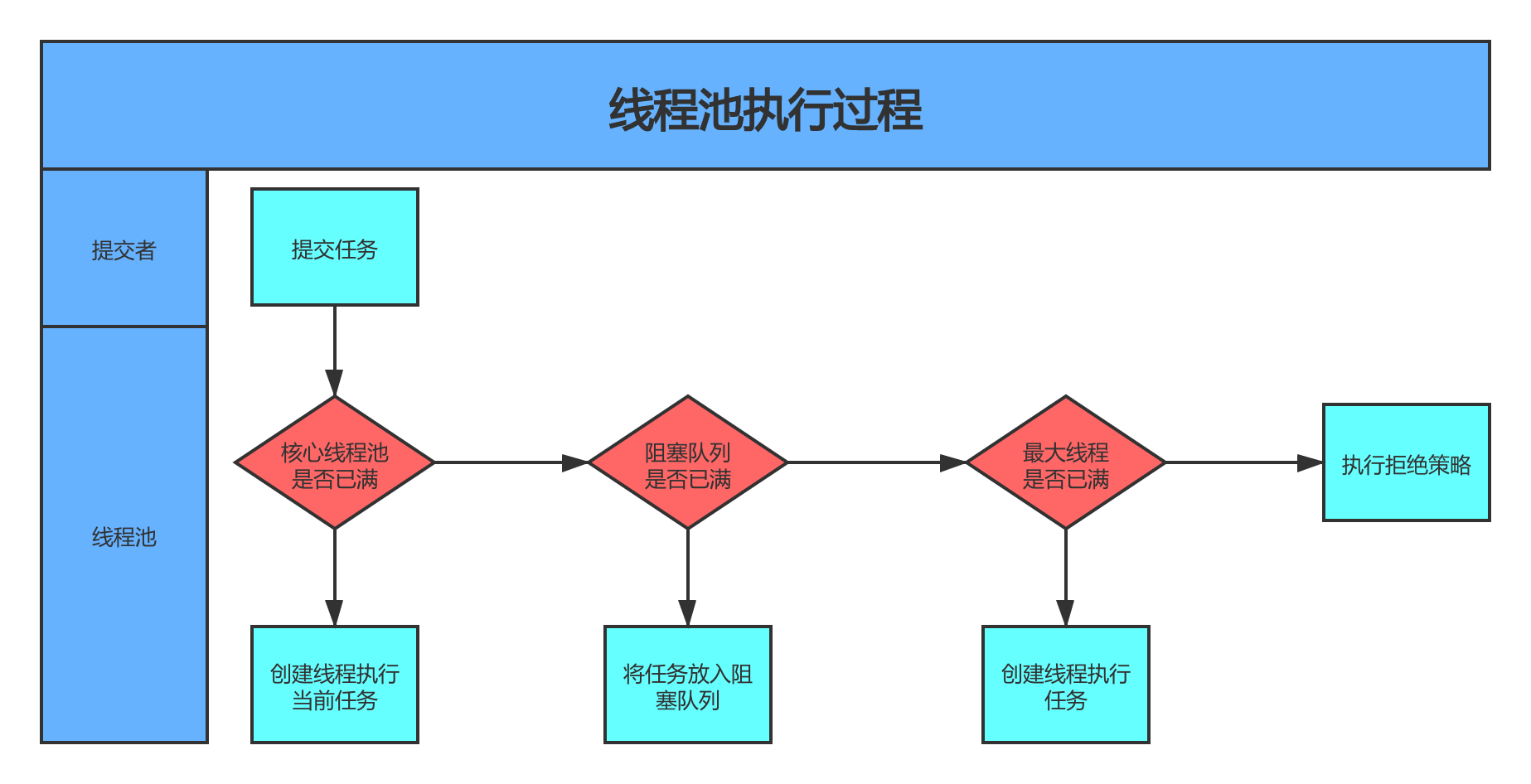
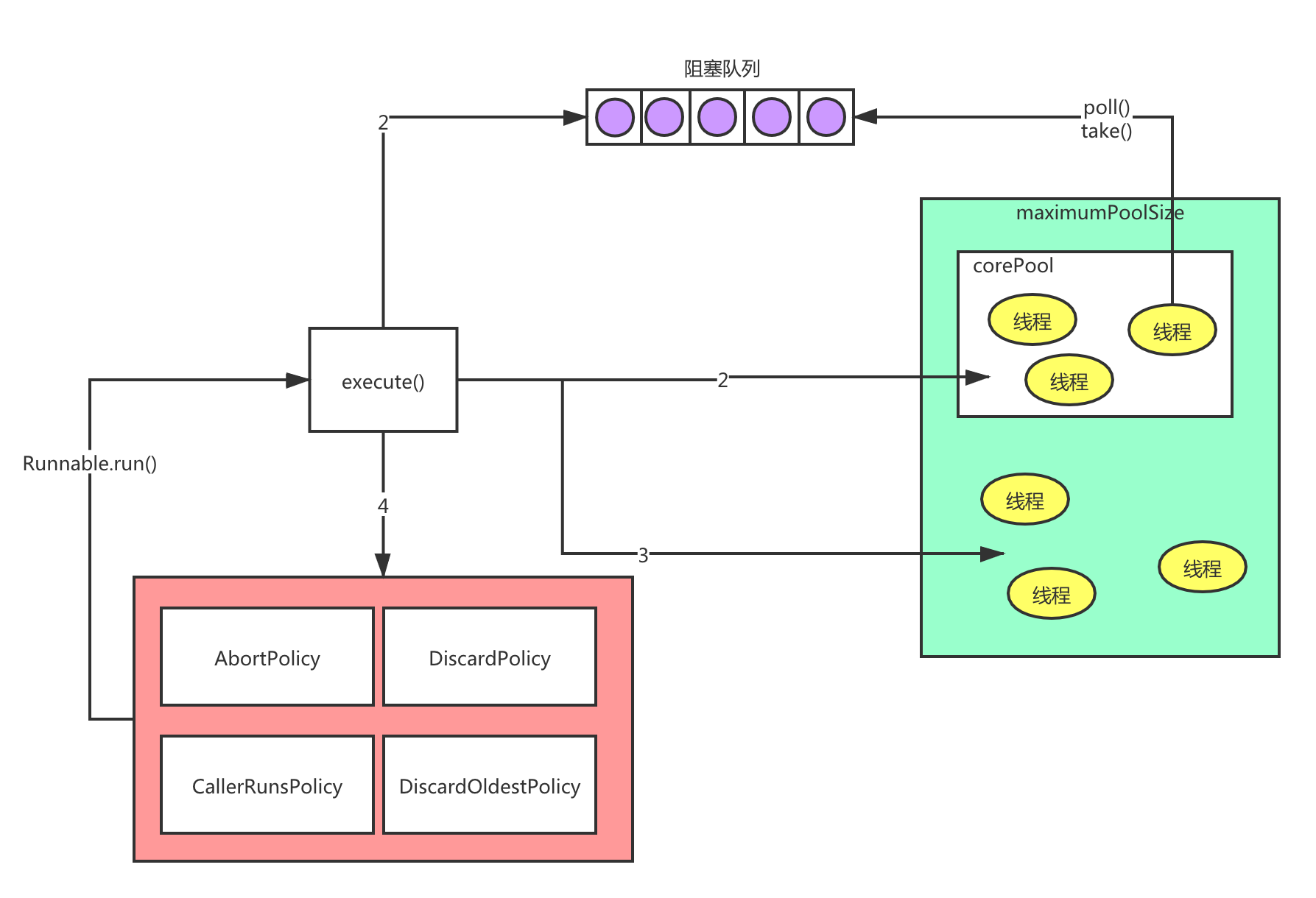
publicvoidexecute(Runnable command) { if (command == null) thrownewNullPointerException(); /* * Proceed in 3 steps: * * 1. If fewer than corePoolSize threads are running, try to * start a new thread with the given command as its first * task. The call to addWorker atomically checks runState and * workerCount, and so prevents false alarms that would add * threads when it shouldn't, by returning false. * * 2. If a task can be successfully queued, then we still need * to double-check whether we should have added a thread * (because existing ones died since last checking) or that * the pool shut down since entry into this method. So we * recheck state and if necessary roll back the enqueuing if * stopped, or start a new thread if there are none. * * 3. If we cannot queue task, then we try to add a new * thread. If it fails, we know we are shut down or saturated * and so reject the task. */ intc= ctl.get(); // worker数量比核心线程数小,直接创建worker执行任务 if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); } // worker数量超过核心线程数,任务直接进入队列 if (isRunning(c) && workQueue.offer(command)) { intrecheck= ctl.get(); // 线程池状态不是RUNNING状态,说明执行过shutdown命令,需要对新加入的任务执行reject()操作。 // 这儿为什么需要recheck,是因为任务入队列前后,线程池的状态可能会发生变化。 if (! isRunning(recheck) && remove(command)) reject(command); // 这儿为什么需要判断0值,主要是在线程池构造方法中,核心线程数允许为0 elseif (workerCountOf(recheck) == 0) addWorker(null, false); } // 如果线程池不是运行状态,或者任务进入队列失败,则尝试创建worker执行任务。 // 这儿有3点需要注意: // 1. 线程池不是运行状态时,addWorker内部会判断线程池状态 // 2. addWorker第2个参数表示是否创建核心线程 // 3. addWorker返回false,则说明任务执行失败,需要执行reject操作 elseif (!addWorker(command, false)) reject(command); }
privatefinalclassWorker extendsAbstractQueuedSynchronizer implementsRunnable { /** * This class will never be serialized, but we provide a * serialVersionUID to suppress a javac warning. */ privatestaticfinallongserialVersionUID=6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */ final Thread thread; /** Initial task to run. Possibly null. */ Runnable firstTask; /** Per-thread task counter */ volatilelong completedTasks;
/** * Creates with given first task and thread from ThreadFactory. * @param firstTask the first task (null if none) */ Worker(Runnable firstTask) { setState(-1); // inhibit interrupts until runWorker this.firstTask = firstTask; // 这儿是Worker的关键所在,使用了线程工厂创建了一个线程。传入的参数为当前worker this.thread = getThreadFactory().newThread(this); }
/** Delegates main run loop to outer runWorker */ publicvoidrun() { runWorker(this); }