
PT-OSC 添加唯一索引导致数据丢失问题分析
背景描述
最近新开发了一个业务功能,在线上创建了一张和这个业务相关的数据表,由于这是一个中间数据表,是将源头数据表进行逻辑处理后临时存储。系统上线后,先从源头表计算了一些数据存储到了新创建的中间数据表,不过在查询中间数据表数据进行后续逻辑处理时,发现查询很慢,原因也很简单,有一个查询索引漏掉了,没有创建,这些都没有什么问题,由于是操作线上数据库,执行相关操作需要走公司内部审批流,直接将以前创建索引的一条 SQL 语句拿来改了一下直接就提交了。
1 | alter table tableA add unique index uniq_test(test); |
这个时候重点来了,其实我本意是创建一个普通索引的,但是没有发现拷贝以前的 SQL 语句创建的是唯一索引,其实创建索引的字段还真是不唯一的,但是即使如此,执行流程还是正常结束了,唯一索引创建成功。
开始似乎也没发现什么问题,索引创建成功了,查询也快了,但是查询结果死活和源头数据表对不上了,想了好长时间不知道为什么,开始以为是自己代码逻辑问题,但是代码逻辑是经过测试的,数据对不上问题很明显,不可能测试没发现。
剩下的故事就是灵光一现的问题了,突然想到线上生产数据库执行 DDL 操作时都是使用的 pt-online-schema-change(简称 pt-osc) 工具,是不是这个工具搞的鬼,马上 google 了一下,很容易就查到了,pt-osc 工具在非唯一字段上创建唯一索引会导致数据丢失。又和公司的 DBA 求证了一下,DBA 坦然承认,pt-osc 工具确实存在这个问题。
毕竟不是专业 DBA,对这个工具只是有基本了解,只知道这个工具执行 DDL 语句时不会锁表,因此不会阻塞数据的写入。
PT-OSC 工具工作原理
pt-osc 工作流程
创建一个和要执行
alter操作的表一样的新的空表,后缀默认是new;在新表执行
alter table语句,因为是空表,执行速度很快;在原表中创建触发器 3 个触发器分别对应
insert、update、delete操作;以一定块大小从原表拷贝数据到临时表,拷贝过程中通过原表上的触发器在原表进行的写操作都会更新到新建的临时表,注意这里是
Replace操作;表名替换 将原表名
table修改为table_old,将table_new表名修改为原表名table;如果有参考该表的外键,根据
alter-foreign-keys-method参数的值,检测外键相关的表,做相应设置的处理;默认最后将旧原表删除。
PS. 这个流程我并没有在官网找到详细的描述,来源于网上的二手资料,不过可以说明问题了,后续找到官网的详细描述再更新。
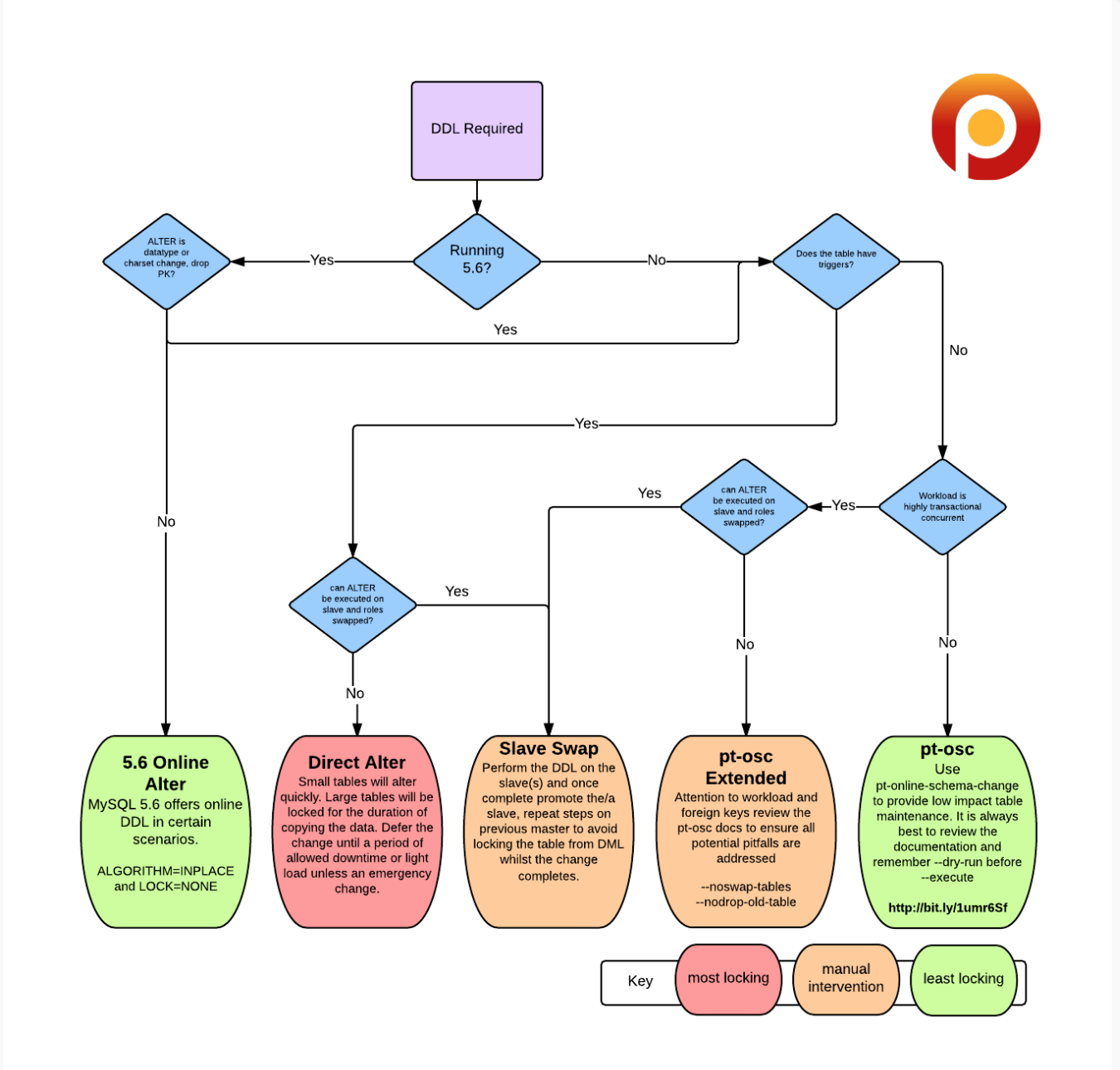
从网上摘抄一个 pt-osc 工具实际运行过程日志输出,公司内部日志输出也是类似的,涉及具体线上业务,就不截图我们线上的内容了。
1 | tmp_task_user |
在 Percona Toolkit 的 jira 问题列表中我们搜索到了相同的问题,在 2017年 就有人提出过:pt-online-schema change eats data on adding a unique index
在这个问题里有描述异常出现的原因:
The cause of the unexpected behavior is that pt-osc uses INSERT LOW_PRIORITY IGNORE to copy chunks, which only raises a warning instead of an error when there is a UNIQUE constraint violation (Percona and Oracle 5.6.35) so pt-osc silently ignores those rows.
引起这个异常行为是由于 pt-osc 工具使用 INSERT LOW_PRIORITY IGNORE 命令来拷贝块数据,这个命令在数据违反唯一约束时只会给出一个警告提示,而不是提示错误,所以 pt-osc 工具默认忽略了这些数据。
不过看这个问题的最终状态是在 3.0.3 版本已经被修复,看问题评论,修复的方式是新增了 use-insert-ignore 参数,这个参数的作用是控制是否在 INSERT 数据时使用 IGNORE 参数。
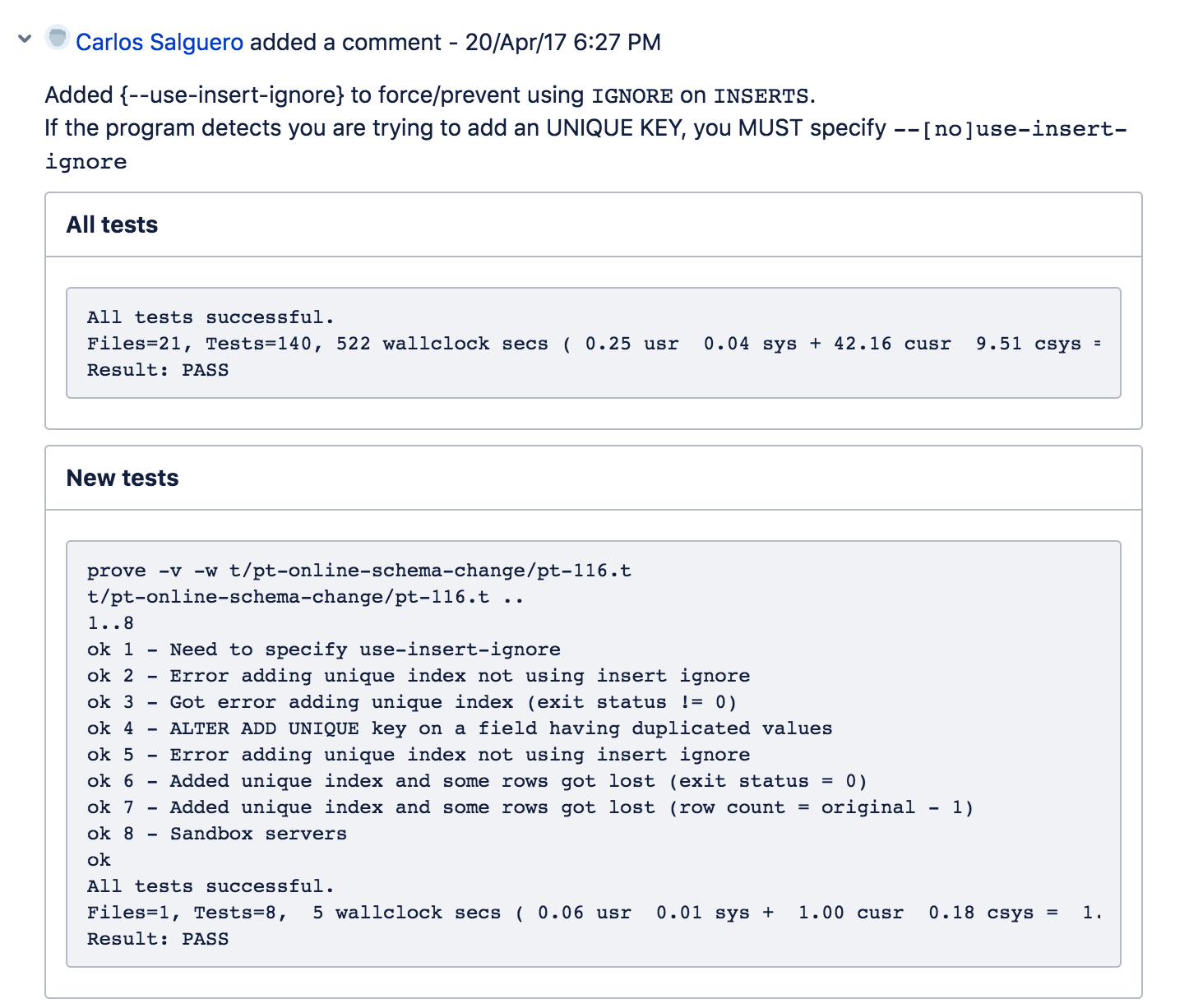
我当时联系了 DBA,找他求证了一下线上生产环境使用的 pt-osc 工具版本,并和求证了一下线上是否开启了这个参数,DBA 回复说现在线上使用比较多的版本还是 2.2.20,当时内心是万马奔腾啊,不过他马上在自己本地环境的 3.0.5 版本上查了一下这个参数使用:
1 | ./pt-online-schema-change --help |
DBA 反馈说并没有这个参数,这个有点奇怪了,还是想自己验证一下,VMware 虚拟机启动了一台测试的 CentOS 7,安装了最新版 pt-osc 工具,也 --help 了一下,发现还真没有参数,而且官网上使用说明也没有这个参数,又是万马奔腾啊。
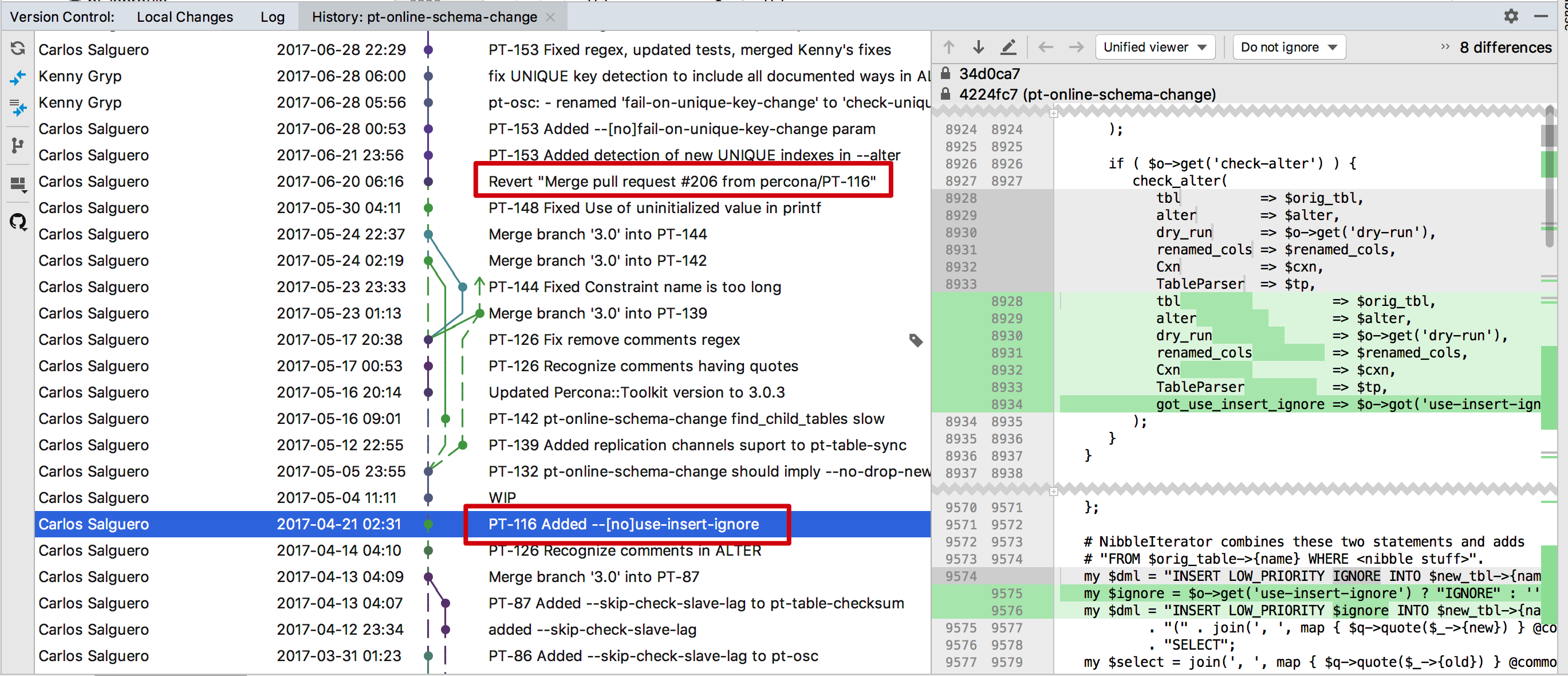
最后只能出大招了,撸源码。首先先在 github 上面搜索了一下 use-insert-ignore 这个参数,找到了 bug 修改记录中有记录这个内容,这个配置是添加在 /bin/pt-online-schema-change shell 脚本中,从 github 上 clone 了一份 percona-toolkit 代码,从最新代码的 pt-online-schema-change 文件中没有搜到这个 use-insert-ignore 参数,然后翻了一遍 pt-online-schema-change 脚本的修改记录,根据 3.0.3 大致发布的时间,终于找到了提交记录,在 2017-04-21 02:31 的提交记录中添加了这个参数,也找到了这个提交的 PR PT-116 pt-online-schema change eats data on adding a unique index,没问题,这个参数一定是存在过的,不过为什么现在最新的是没有这个参数的,究竟在哪里又被去掉了呢?继续翻记录,还好在不远处的提交就找到了原因,在 2017-06-20 06:16 的一次提交,将上一次的提交直接 revert 掉了,而且没有写什么原因,这次 revert 貌似没有 github 的 PR 记录,本来想到 github 上面提个 issue 问一下这个问题,在进到代码库地址,重点到了,居然不能提 issue,好了,就到这里了,这个参数也只就是昙花一现了。
事故总结
首先这是一个不幸的事情,线上出现了事故;但是这也是一个幸运的事情,因为出现问题只是一个中间数据表,不是核心业务源头数据表,如果是核心数据表,不好说后果了;而且及早发现了这个问题,至少比以后出现更严重事故要好的多,踩坑还是得趁早。
工作上还是有疏忽,即使再怎么认真的去对待工作,还是会有疏漏时候,对于线上生产环境的操作,即使感觉安全的,也会有一定的风险,避免风险的方式可以参考敏捷开发中的 结对编程 的思想,对于线上的重要操作,由自己的一名队友确认之后,再进行操作,这也是我目前工作的思路转变,双人确认之后再执行操作。
最后是工作流程上的一种反思,我们现在线上数据库操作,是有公司内部的审批流的,但是这个审批流程的节点是 M 岗的管理人员,管理人员对于具体的技术操作可能了解并不多,所以现在的审批流程形式大于意义;对于这个审批工作,更应该交给技术岗的研发负责人或者架构师来完成,能够熟悉正在操作修改的内容,仔细确认修改内容是否合理,是否准确,严格把握审批流程,可能在工作流程上更合理。