
Redis 常用数据结构及其底层存储实现总结
背景介绍
Redis 是一个开源的,使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存亦可持久化的日志型、Key-Value 数据库,对于 Key-Value 数据库的使用场景,Redis 都有非常广泛的应用。Redis 之所以很受欢迎,非常流行,与其丰富的数据类型,能够满足很多不同的场景应用是密不可分。这一篇文章,我们就一起来总结一下 Redis 常用的数据结构以及对应数据结构的底层存储结构的实现。
Redis 测试版本:Redis-6.3.2
常用数据类型总结
对于目前的项目开发中,我们常用的数据结构有如下几种:
string类型,用于存储:字符串、整形、浮点型数据;hash类型,用于存储 Key-Field-Value 类型数据;list类型,集合类型,用于存储集合元素,元素内容可以重复,按元素添加顺序排序;set类型,集合类型,用于存储集合元素,元素内容不可以重复,集合元素无序;sorted set类型,集合类型,用于存储集合元素,元素内容不可以重复,可以为每一个元素设置一个分值,可以根据分值进行排序。
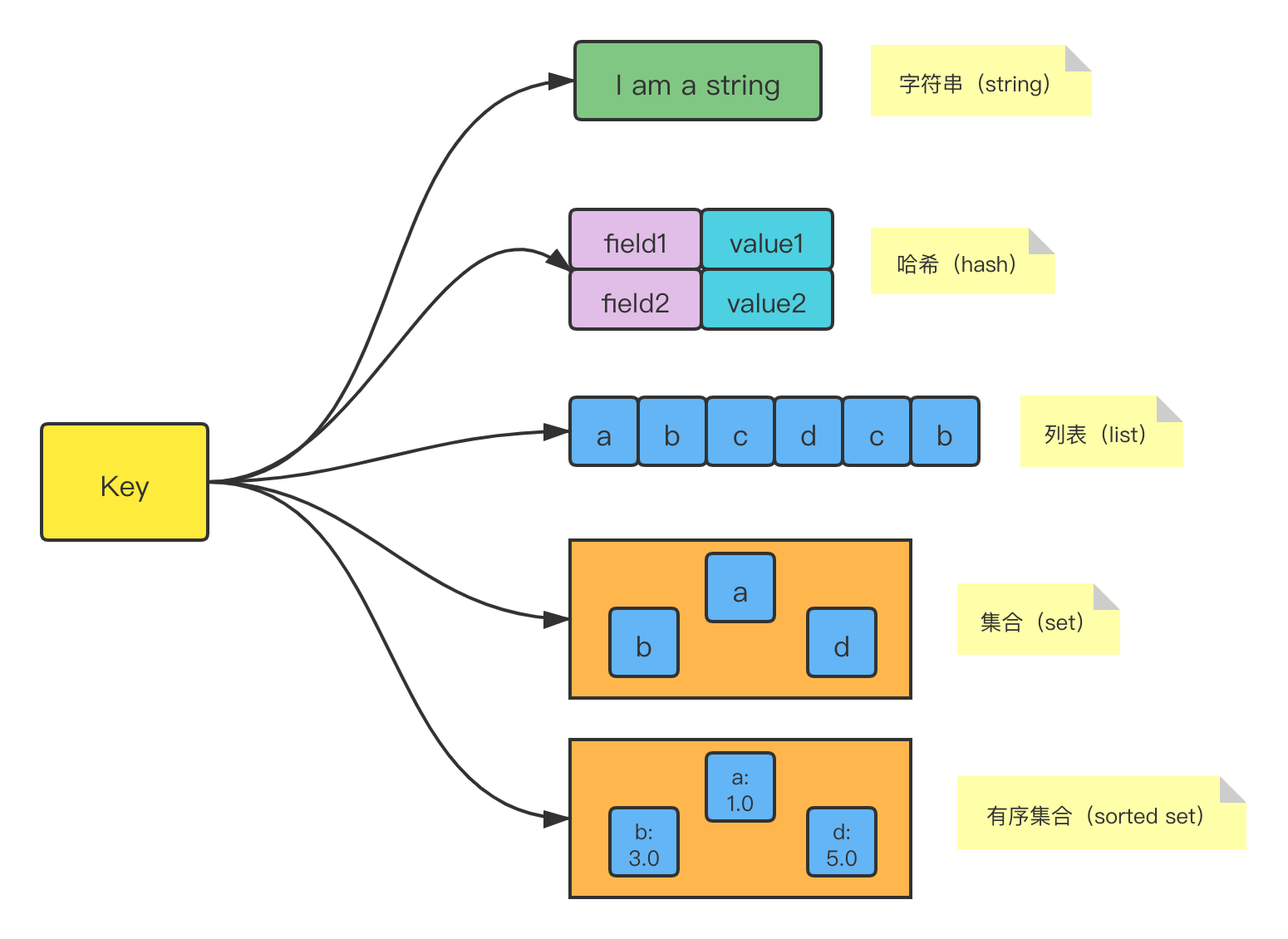
在 Redis 中我们可以 type 命令查看某个 Key 对应的数据结构的类型。
1 | 127.0.0.1:6379> set test test |
常用数据类型存储结构
存储结构总结
在 Redis 中,对于某种数据类型,底层会使用多种存储结构来实现,如下图:
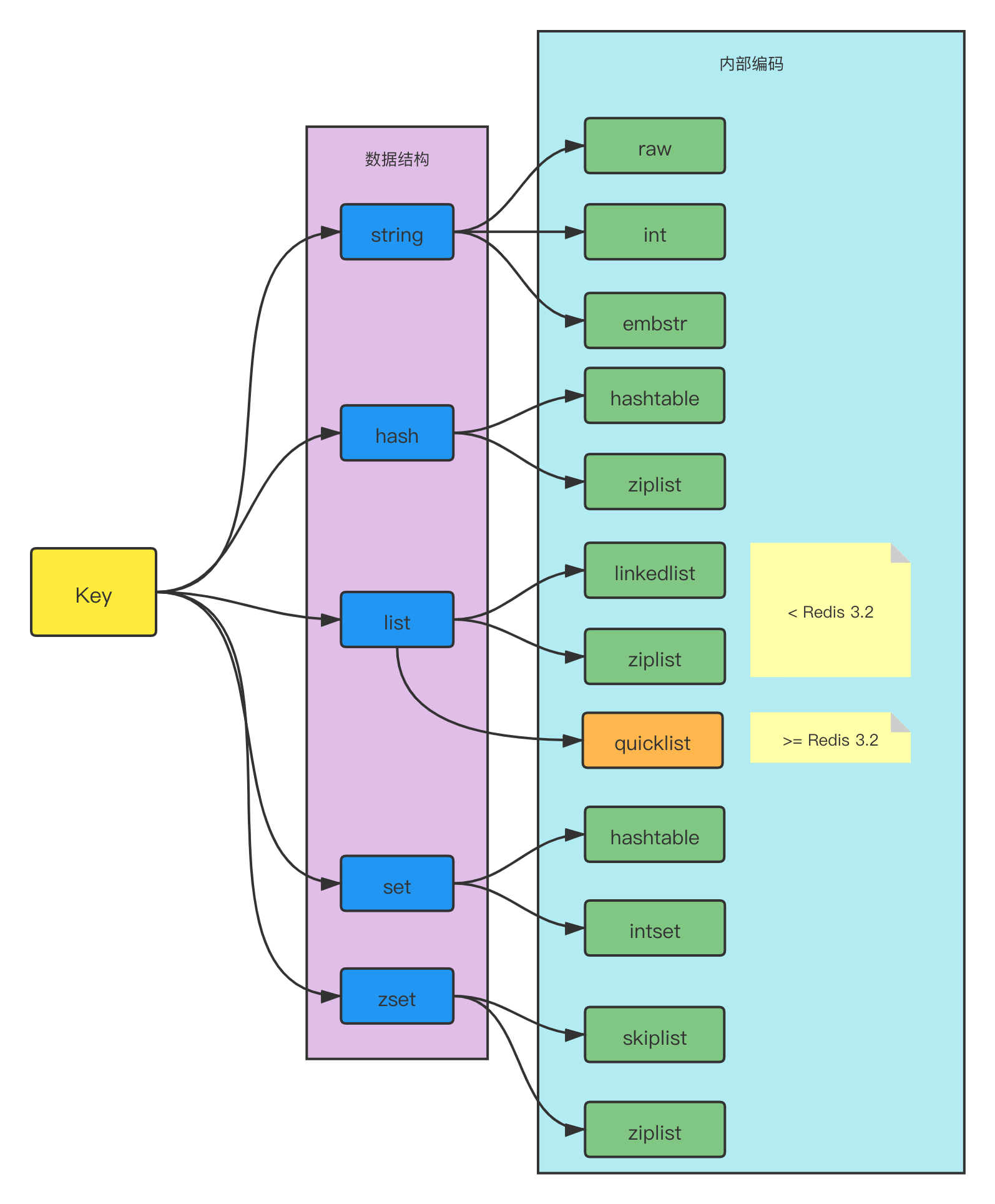
实现方案优势分析
对于某种数据类型,在底层使用多种存储结构来实现,会有如下好处:
可以随时改进内部存储结构的编码实现,而对外的数据结构和命令全都没有影响,这样一旦开发出更优秀的内部存储结构,无需改动外部的数据结构和命令,例如
Redis 3.2中提供了quicklist存储结构,结合了ziplist和linkedlist两者的优势,为list类型数据结构提供了一种更为优秀的内部编码实现,而对外部用户来说基本感知不到。多种内部编码实现可以在不同场景下发挥各自的优势,例如
ziplist比较节省内存,但是在hash元素比较多的情况下,性能会有所下降,这时候Redis会根据配置选项将hash类型内部存储结构转换为hashtable。
存储结构详细分析
string 类型存储结构
string 类型的内部存储结构有 3 种:
int:8个字节的长整型;embstr:小于等于39个字节的字符串;raw:大于39个字节的字符串。
Redis 会根据当前值的类型和长度决定使用哪种存储结构来实现。
1 | 127.0.0.1:6379> set test 6379 |
hash 类型存储结构
hash 类型底层的存储结构有如下两种:
ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)。
1、当 field 个数比较少且没有大的 value 时,存储结构为 ziplist:
1 | 127.0.0.1:6379> hmset test1 f1 v1 f2 v2 f3 v3 |
2、当有 value 大于 hash-max-ziplist-value 配置(默认 64)字节时,内部编码会由 ziplist 变为 hashtable:
1 | 127.0.0.1:6379> hset test1 f4 "Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache, and message broker. Redis provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. Redis has built-in replication, Lua scripting, LRU eviction, transactions, and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster." |
3、当 field 个数超过 hash-max-ziplist-entries 配置(默认 512 个),内部编码也会由 ziplist 变为 hashtable。
1 | public static void main(String[] args) throws Exception { |
1 | 127.0.0.1:6379> object encoding test |
list 类型存储结构
list 类型底层的存储结构有如下两种:
ziplist(压缩列表):当列表的元素个数小于list-max-ziplist-entries配置(默认512个),同时列表中每个元素的值都小于list-max-ziplist-value配置时(默认64字节),Redis会选用ziplist来作为列表的内部实现来减少内存的使用。linkedlist(链表):当列表类型无法满足ziplist的条件时,Redis会使用linkedlist作为列表的内部实现。
由于我测试使用的版本是 Redis-6.3.2,上述两个关于 list 类型数据结构的参数已经被废弃,同时对于 list 数据结构底层的存储实现统一使用 quicklist 存储结构,示例如下:
1 | 127.0.0.1:6379> rpush test e1 e2 e3 e4 |
在 Redis 3.2 版本之后,Redis 统一使用 quicklist 存储结构实现了 list 类型数据结构,同时设置了两个参数来满足不同应用场景下使用需求:
list-max-ziplist-size:该配置参数取正值时表示quicklist节点ziplist包含的数据项。取负值表示按照占用字节来限定quicklist节点ziplist的长度。-5: 每个quicklist节点上的ziplist大小不能超过64Kb;-4: 每个quicklist节点上的ziplist大小不能超过32Kb;-3: 每个quicklist节点上的ziplist大小不能超过16Kb;-2: 每个quicklist节点上的ziplist大小不能超过8Kb;(默认配置)-1: 每个quicklist节点上的ziplist大小不能超过4Kb。
list-compress-depth:list数据结构最容易被访问的是列表两端的数据,中间的访问频率很低,如果符合这个场景,list可以通过配置参数设置对中间节点进行压缩,进一步节省内存。配置如下:0: 是个特殊值,表示都不压缩;(默认配置)1: 表示quicklist两端各有1个节点不压缩,中间的节点压缩;2: 表示quicklist两端各有2个节点不压缩,中间的节点压缩;- 以此类推。
set 类型存储结构
set 类型底层的存储结构有如下两种:
intset(整数集合):当集合中的元素都是整数且元素个数小于set-max-intset-entries配置(默认512个)时,Redis会选用intset来作为集合的内部实现,从而减少内存的使用。hashtable(哈希表):当集合类型无法满足intset的条件时,Redis会使用hashtable作为集合的内部实现。
1、当元素个数较少且都为整数时,内部编码为 intset:
1 | 127.0.0.1:6379> sadd test 1 2 3 4 5 |
2、当元素个数超过 set-max-intset-entries 配置(默认 512 个),内部编码变为 hashtable:
1 | public static void main(String[] args) throws Exception { |
1 | 127.0.0.1:6379> object encoding test |
3、当某个元素不为整数时,内部编码也会变为 hashtable:
1 | 127.0.0.1:6379> sadd test 1 2 3 4 5 |
sorted set 类型存储结构
sorted set 类型底层的存储结构有如下两种:
ziplist(压缩列表):当有序集合的元素个数小于zset-max-ziplist-entries配置(默认128个),同时每个元素的值都小于zset-max-ziplist-value配置(默认64字节)时,Redis会用ziplist来作为有序集合的内部实现,ziplist可以有效减少内存的使用。skiplist(跳跃表):当ziplist条件不满足时,有序集合会使用skiplist作为内部实现,因为此时ziplist的读写效率会下降。
1、当元素个数较少且每个元素较小时,内部编码为 skiplist:
1 | 127.0.0.1:6379> zadd test 10 e1 11 e2 12 e3 13 e4 |
2、当元素个数超过 zset-max-ziplist-entries 配置(默认 128 个)数量,内部编码变为 skiplist:
1 | public static void main(String[] args) throws Exception { |
1 | 127.0.0.1:6379> object encoding test1 |
3、当某个元素大于 zset-max-ziplist-value 配置(默认 64)字节数时,内部编码也会变为 skiplist:
1 | 127.0.0.1:6379> zadd test 10 e1 11 e2 12 e3 13 e4 |
总结
Redis 是一个高性能的 Key-Value 型内存数据库,它给我们提供了丰富的数据结构来满足不同业务场景的需要,针对不同的数据结构 Redis 底层也设计了多种不同的存储实现,其实主要的目的总结起来主要就是两点:
灵活可扩展;
高性能,节约内存。
所有的设计我认为都是基于以上两点展开的,针对不同数据类型采用多种存储结构,可以灵活改进内部存储结构的编码实现,而对外的数据结构和命令全都没有影响,这样一旦开发出更优秀的内部存储结构,无需改动外部的数据结构和命令;同时多种内部编码实现可以在不同场景下发挥各自的优势,例如针对 hash 数据结构,Redis 底层设计了 ziplist 和 hashtable 两种存储结构,当哈希类型元素个数比较少时(小于 hash-max-ziplist-entries)并且所有元素 Value 值都小于 hash-max-ziplist-value 字节时,使用 ziplist 存储结构,这种存储结构更加紧凑,多个元素可以联系存储,比较节省内存;但是一旦元素个数过多,或者存储 Value 值比较大,这时 ziplist 的读写效率会下降,性能会变差,Redis 会自动转换为 hashtable 存储结构,这种存储结构虽然会浪费一些内存空间,但是读写效率会比较高。
所以,我们也可以体会到,实现一个优秀的软件架构其实就是一个不断 Trade-Off 的过程。