
使用 ClickHouse 作为 MySQL 的数据分析扩展
原文链接:https://www.percona.com/blog/using-clickhouse-as-an-analytic-extension-for-mysql/
MySQL 是一款出色的用于在线事务处理的数据库。搭配合适的硬件,MySQL 可以轻松的每秒处理超过百万查询并处理数万个并发连接。在我们这个星球上许多要求非常苛刻的 Web 应用程序都是基于 MySQL 构建的。有了这样的能力,为什么使用 MySQL 的用户还需要其他工具?
那好,首先考虑的是分析查询,分析查询可以回答很多重要的业务问题,例如查找一段时间内访问过网站的唯一身份用户数量,或者弄清楚如何增加在线购买量。分析查询会扫描大量数据并进行聚合运算,包括求和、求平均值以及其他更复杂的计算,计算的结果有非常大的价值,但分析查询过程可能会影响在 MySQL 上运行的联机事务的性能。
幸运的是,还有 ClickHouse:一个功能强大的分析型数据库,可以与 MySQL 完美搭配。Percona 与我们的合作伙伴 Altinity 密切合作,帮助用户轻松地将 ClickHouse 嵌入到现有的 MySQL 应用程序中。您可以在我们最近的新闻稿中阅读更多关于我们合作伙伴关系的信息,以及我们实现的 MySQL-to-ClickHouse 解决方案。
这篇文章给出了一些提示,如何识别 MySQL 何时分析任务过重以及如何使用 ClickHouse 的独特功能并从中受益。然后,我们展示了将 MySQL 和 ClickHouse 集成到一起的三种重要方式。充分利用这两种数据库的优势的结果是可以创建更强大、更具成本效益的应用程序。
MySQL 需要辅助分析工具的迹象
让我们首先深入研究一些明显的迹象,这些迹象表明我们的 MySQL 数据库因处理分析工作而负担过重。
数据量巨大的不变数据表与在线事务表混合在一起
数据分析的驱动表往往数据量非常大,很少有数据更新,并且表可能还会有很多列。典型示例是 Web 访问日志数据、营销活动事件数据和监控数据。如果我们观察到一些异常大的不可变数据表与较小的、频繁更新的事务处理表混合在一起,此时添加一个单独的分析型数据库会给用户带来非常大的益处。
复杂的聚合管道
分析处理产生聚合结果,这些聚合操作能够汇总大型数据集生成统计数据以帮助用户进行模式识别。这些示例包括每周站点唯一访问者、平均页面用户流失率或网络流量来源。MySQL 可能需要几分钟甚至几小时来计算这些数值结果,为了提高性能,通常会预先添加聚合计算的复杂批处理流程。如果我们看到这样的聚合管道,通常表明添加单独的分析数据库可以减少操作应用程序的工作量,并可以更快、更及时地为用户提供结果。
MySQL 太慢或不够灵活,无法解答重要的业务问题
最后一条线索是有关基于 MySQL 的应用程序的深入问题,我们不要问,因为很难得到答案。为什么用户不在电子商务网站上完成购买?哪种游戏内促销策略在多人游戏中收益最大?直接从 MySQL 事务数据回答这些问题通常需要大量时间,并需要额外的应用程序。这些问题其实很难回答,大多数用户也根本不会关心,不过将 MySQL 与功能强大的分析数据库相结合可能是一种可行的解决方案。
为什么 ClickHouse 是 MySQL 的天然补充?
MySQL 是用于事务处理的杰出数据库。然而,使 MySQL 高效运行的特性——按行存储数据、单线程查询和针对高并发特性的优化——与在大型数据集上执行聚合计算的分析查询所需要的特性恰恰相反。
另一方面,ClickHouse 是为分析处理而设计的。它将数据存储在列中,并进行了优化,以最小化 I/O 非常高效地执行聚合计算,并进行并行化查询优化。在许多情况下,ClickHouse 几乎可以立即响应复杂的分析问题处理,从而使用户可以快速筛选数据,因为 ClickHouse 计算聚合的效率很高,所以最终用户可以在没有应用程序设计人员帮助的情况下以多种方式处理问题。
这些都是非常有力特性说明,要了解它们,了解 ClickHouse 与 MySQL 的不同之处会很有帮助,下图说明了每种数据库为读取某张表的三列数据是如何通过查询提取数据的。
MySQL 是按行存储表数据,它必须读取整行来获取仅三列的数据。MySQL 生产系统通常也不使用压缩,因为它在事务处理方面存在性能缺陷。最后,MySQL 使用单线程进行查询处理,无法并行工作。
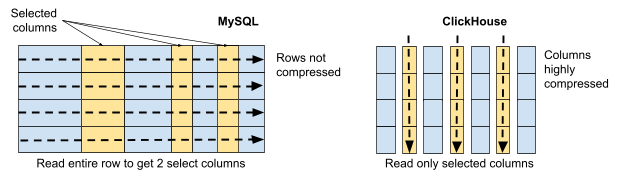
相比之下,ClickHouse 可以只读取查询中引用的列,将数据存储在列中使得 ClickHouse 能够将数据压缩超过 90%,最后 ClickHouse 将表分段存储后可以使用并行扫描。

MySQL 和 ClickHouse 给出了相同的答案。但是为了获得结果,MySQL 读取了 59GB 的数据,而 ClickHouse 只读取了 21MB,这几乎是 3000 倍的 I/O 差距,因此访问数据的时间也相差很多。为了进一步提高性能,ClickHouse 还做了很多优化,可以进行并行化查询,这使得在 ClickHouse 运行的分析查询的运行速度比在 MySQL 上快数百甚至数千倍。
ClickHouse 还提供了一系列丰富的功能,可以快速高效地运行分析查询。其中包括大型聚合函数库、某些场景下可用的SIMD 指令、支持从 Kafka 事件流读取数据以及高效的物化视图能力,这里仅举几个例子。
ClickHouse 最大的一个优势是:可以与 MySQL 进行出色集成,这里有一些例子。
ClickHouse可以将mysqldump和CSV的数据直接提取到ClickHouse表中;ClickHouse可以对MySQL表执行远程查询,这提供了另一种快速提取数据的方法;ClickHouse查询方言与MySQL非常类似,支持例如SHOW PROCESSLIST等系统命令;ClickHouse甚至在3306端口上支持MySQL协议。
由于以上这些原因,ClickHouse 是扩展 MySQL 分析处理能力的天然选择。
为什么 MySQL 是 ClickHouse 的天然补充?
正如 ClickHouse 可以为 MySQL 扩展有益的功能一样,重要的是 MySQL 同样为 ClickHouse 扩展了有益的功能。ClickHouse 在分析处理方面非常出色,但它在很多方面做得并不好,这里有一些示例。
- 事务处理——
ClickHouse没有完整的ACID事务能力,我们不要使用ClickHouse来处理在线订单业务,MySQL在这方面做得很出色; - 单行快速更新——读取某一行数据的所有列在
ClickHouse中效率非常低,因为我们必须读取许多文件;更新单行可能需要重写大量数据,我们不要将电子商务会话数据存储到ClickHouse中,这是MySQL的典型应用场景; - 大量并发查询——
ClickHouse查询旨在使用尽可能多的资源,而不是在许多用户之间共享这些资源,我们不要使用ClickHouse来保存微服务的元数据,但MySQL通常用于此类场景。
事实上,MySQL 和 ClickHouse 是高度互补的。当 ClickHouse 和 MySQL 一起使用时,用户可以构建非常强大的应用程序。
将 ClickHouse 集成进 MySQL
有三种方式可以将 MySQL 数据与 ClickHouse 分析功能集成到一起,它们建立在彼此之上。
- 从
ClickHouse查看MySQL数据,可以使用原生ClickHouseSQL语法通过ClickHouse查询MySQL数据,这对于查询MySQL数据以及与MySQL的数据进行join操作的场景是非常有用的; - 将数据从
MySQL永久迁移到ClickHouse,ClickHouse成为数据的存储系统,这会降低MySQL负载并提供更好的数据分析结果; - 在
ClickHouse存储MySQL数据镜像,将数据快照存入ClickHouse并使用复制机制保持数据同步,这允许用户在不增加交易处理系统负担的情况下分析交易数据的一些复杂问题。
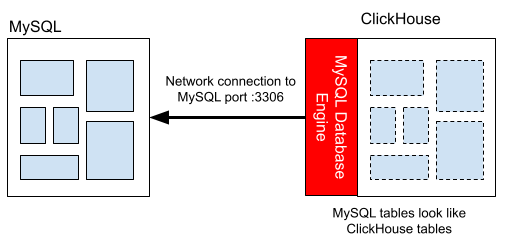
通过 ClickHouse 访问 MySQL 数据
ClickHouse 可以使用MySQL 数据库引擎对 MySQL 数据进行查询,这使得在 ClickHouse 中使用 MySQL 数据就像在使用本地表数据一样,启用这个功能跟在 ClickHouse 上执行单个 SQL 命令一样简单,如下所示:
1 | CREATE DATABASE sakila_from_mysql |
这是有关 MySQL 数据库引擎的简单说明。
MySQL 数据库引擎使得在 ClickHouse 中查询 MySQL 数据并在 ClickHouse 中复制数据变得非常简单。ClickHouse 对远程数据的查询甚至可能比在 MySQL 中运行得更快!这是因为 ClickHouse 有时可以对远程数据进行并行查询。一旦存储了这些数据,ClickHouse 能够提供更加高效的聚合操作。
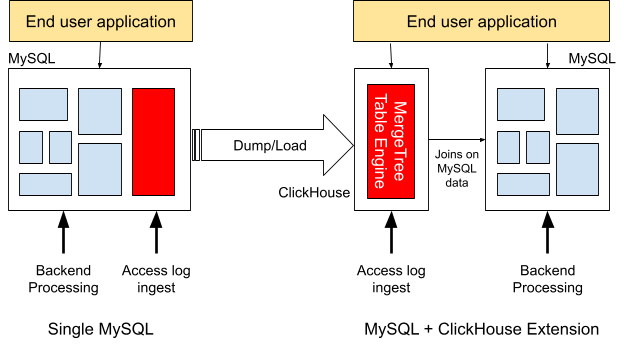
将 MySQL 数据移动到 ClickHouse
将具有不可变记录的大型表永久迁移到 ClickHouse 可以大大提高查询分析的性能,同时降低 MySQL 的负载。下图说明了如何将包含 Web 访问日志的表从 ClickHouse 迁移到 MySQL。(这里作者应该有笔误:从 MySQL 迁移到 ClickHouse)
在 ClickHouse 系统中,我们通常会选择使用 MergeTree 表引擎或其变体之一,例如 ReplicatedMergeTree。MergeTree 是 ClickHouse 上大数据的首选引擎,以下三个重要功能将帮助我们充分利用 ClickHouse。
- 分区——
MergeTree使用分区键将数据分成多个部分。访问日志内容或其他大数据内容往往是按时间排序的,因此通常按天、按周或按月来划分数据;为获得最佳性能,建议设置的分区数少于1000; - 排序——
MergeTree可以对数据进行排序并在行上构建索引以匹配我们所选择的排序。重要的是确定一种排序方式,以便在扫描数据时为我们提供大型“运行”场景;例如我们可以选择按租户排序,然后再按时间排序,这意味着对租户数据的查询不需要跳来跳去查找与该租户相关的数据行; - 压缩和编解码器 ——
ClickHouse默认使用LZ4压缩,但也提供ZSTD压缩和编解码器;编解码器在将列数据转为压缩之前减少数据列内容。
这些特性可以在性能上产生巨大的差异,我们在 Altinity 视频(查看此处和此处)以及博客文章中介绍了它们并添加了更多性能说明。
ClickHouse MySQL 数据库引擎在这种场景下也非常有用,它使 ClickHouse 能够从 MySQL 的远程事务表中查询和选择数据,我们的 ClickHouse 查询可以将本地表与远程的 MySQL 事务表的数据进行连接操作,同时 MySQL 也可以高效且安全地处理事务操作。
将表迁移到 ClickHouse 通常按以下方式进行,我们将使用前面描述的访问日志示例。
- 为
ClickHouse上的访问日志数据创建匹配的schema结构; - 使用以下几种工具将数据从
MySQL转储/加载到ClickHouse:- Mydumper —— 一种处理
mysqldump和CSV格式的并行转储/加载工具; - MySQL Shell —— 用于管理
MySQL导入和导出表的的通用工具; - 在
MySQL数据库引擎表上使用SELECT复制数据; - 本机数据库命令 – 使用
MySQL SELECT OUTFILE将数据转储到CSV并使用ClickHouse INSERT SELECT FROM file()读取数据,ClickHouse甚至可以读取mysqldump格式数据。
- Mydumper —— 一种处理
- 关注性能,确保查询操作是否恰当;对
schema进行调整并在必要时重新加载; - 收集前端访问日志存储到
ClickHouse; - 并行运行两个系统进行测试工作;
- 从单独的
MySQL架构切换到MySQL+ClickHouse扩展架构。
迁移可能只需要几天时间,但在大型系统中更常见的是需要几周到几个月的时间,这有助于确保一切都经过充分的测试,并顺利上线运行。
在 ClickHouse 中存储 MySQL 数据镜像
另一种扩展 MySQL 的方法是将数据作为镜像存储到 ClickHouse 中,并使用复制机制保持数据同步。镜像允许用户在不更改 MySQL 及其应用程序,并且不影响生产系统性能的情况下,对交易数据执行复杂的查询分析操作。
以下是镜像设置的工作机制。
ClickHouse 有一种内置的方式来处理镜像:实验性的MaterializedMySQL 数据库引擎,它直接从 MySQL 主数据库读取 binlog 日志记录,并将数据复制到 ClickHouse 表中。这种方法很简单,但是还未在生产系统广泛使用。它可能对 1 对 1 镜像场景非常有用,但在生产系统广泛使用之前需要额外的测试工作。
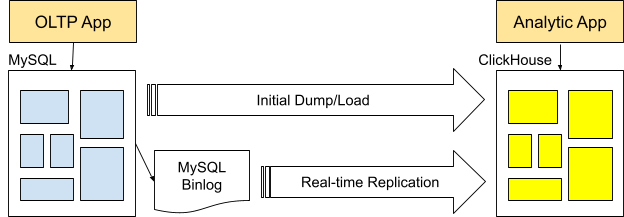
Altinity 使用Debezium、兼容Kafka的事件流和用于ClickHouse 的 Altinity Sink Connector开发了一种新的复制方法。镜像配置如下所示。
外部化方案有许多优点,它们包括当前使用的 ClickHouse 版本,利用快速转储/加载程序(如 mydumper 或使用 MySQL 数据库引擎直接进行 SELECT 操作),支持镜像到复制表,以及添加新表或重置旧表等等一些简单过程。最后,它可以扩展支持将多个上游 MySQL 系统复制到单个 ClickHouse 集群。
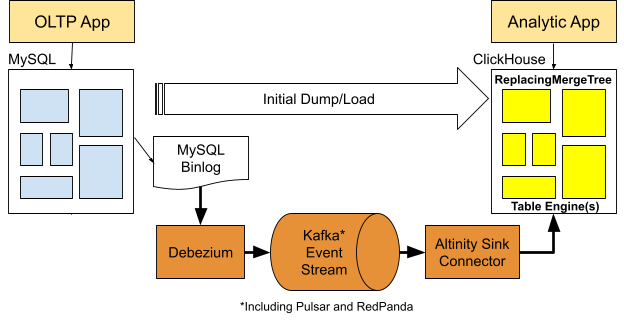
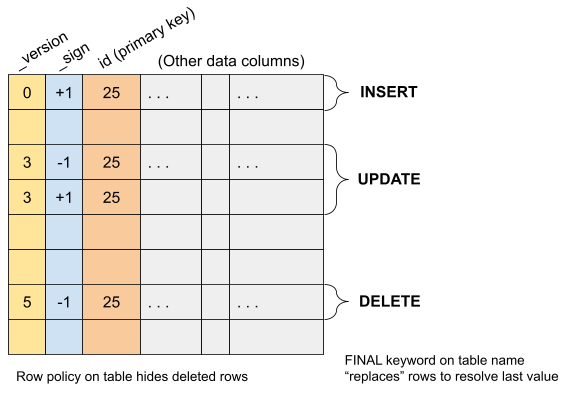
由于ReplacingMergeTree表的独特功能,ClickHouse 可以从 MySQL 拉取镜像数据。它有一种处理插入、更新和删除的有效方法,非常适合用于复制数据。如前所述,ClickHouse 无法轻松更新单行数据,但它插入数据的速度非常快,并且可以在后台高效地合并数据行。ReplicatingMergeTree 以这些功能为基础,以ClickHouse 方式处理数据变更。
复制的表行使用版本和符号列来标识更改行的版本以及更改是插入还是删除操作。ReplacingMergeTree 只会保留一行的最后一个版本,实际上这一行可能已被删除。符号列让我们使用另一个 ClickHouse 特性使那些已被删除的行不可访问,被称为行策略。使用行策略,我们可以确保符号列为负数的任何行不可见。
下面是 ReplacingMergeTree 的一个示例,它结合了版本和符号列的效果来处理可变数据。
将数据镜像到 ClickHouse 可能看起来比迁移更复杂,但实际上相对简单,因为不需要更改 MySQL 架构或应用程序,并且 ClickHouse 架构存储镜像数据遵循通用的模式。实施过程包括以下步骤:
- 在
ClickHouse中为复制表创建schema; - 配置并运行从
MySQL到ClickHouse的复制; - 使用与迁移相同的工具将数据从
MySQL转储/加载到ClickHouse。
此时,用户可以自由地开始在 ClickHouse 上运行分析或构建其他应用程序,同时不断从 MySQL 复制更改数据。
工具仍在不断提升!
MySQL 到 ClickHouse 的数据迁移是 Altinity 和整个 ClickHouse 社区都在积极推进的一个领域。改进分为三大类:
转储/加载工具——Altinity 正在开发一种新的实用程序来迁移数据,减少模式创建和数据传输到单一集群的工作内容。我们将在以后的博客文章中对此进行更多讨论;
复制——Altinity 正在赞助开发 ClickHouse 的 Sink Connector,它可以自动执行高速复制,包括监控功能,并集成到 Altinity.Cloud 中,我们的目标同样是将复制设置减少到单个命令;
ReplacingMergeTree——目前用户必须在表名中包含 FINAL 关键字以强制合并数据变更,还需要添加行策略,让被删除的行自动隐藏。正在开发的 pull requests 添加了 MergeTree 属性实现在查询中自动添加 FINAL 以及使已被删除的行即使在没有行策略的情况下自动隐藏,它们一起工作将数据复制更新和数据删除的处理对用户完全透明。
我们也在仔细观察 MaterializedMySQL 的改进以及其他高效集成 ClickHouse 和 MySQL 的方法。我们可以期待将来有更多关于这些和相关主题的博客文章。敬请关注!
总结并重新起航
ClickHouse 是对现有 MySQL 应用程序的强大补充。具有不可变数据的大型表、复杂的聚合管道操作以及有关 MySQL 事务的未解决问题都是明确的特征,表明集成 ClickHouse 是为用户提供快速、高效的数据分析的下一步选择。
根据我们的应用程序,使用复制将数据镜像到 ClickHouse 或者将一些表迁移到 ClickHouse 可能是很有意义的。ClickHouse 已经可以与 MySQL 很好地集成,并且很快就会有更好的工具出现。不用说,Altinity 在该领域的所有贡献都是开源的,在 Apache 2.0 许可下发布。
最重要的一点是从 MySQL 和 ClickHouse 共同工作的角度来思考,而不是将其视为一个替代另一个。每个数据库都有独特而持久的优势,最好的应用程序将建立在这些之上,为用户提供比单独使用任何一个数据库更快、更灵活的功能。
开源数据库领域的知名专家 Percona 与 Altinity 合作,为 MySQL 应用程序提供强大的分析能力。如果您想了解更多关于 MySQL 与 ClickHouse 集成的信息,请随时联系我们或在我们的论坛上留言。