
解决大规模问题的 10 个系统设计算法、协议和分布式数据结构
朋友们大家好,如果我们正在准备系统设计面试,那么我们应该关注的一件事情:学习不同的系统设计算法以及研究这些算法能够在分布式系统和微服务中解决的问题。
在过去的文章中,我分享了7 个系统设计问题和10 个系统设计基本概念两篇文章;在本文中,我将继续分享每个开发人员都应该学习的 10 个系统设计算法。
事不宜迟,以下是可用于解决大规模分布式系统问题的 10 种系统设计算法和分布式数据结构:
- 一致性哈希(
Consistent Hashing) MapReduce- 分布式哈希表(
Distributed Hash Tables(DHT)) - 布隆过滤器(
Bloom Filters) - 两阶段提交(
Two-phase commit(2PC)) PaxosRaftGossip协议(Gossip protocol)ChordCAP理论(CAP theorem)
这些算法和分布式数据结构只是用于解决大规模分布式系统问题的众多技术中的几个例子。
面向程序开发人员的 10 大分布式数据结构和系统设计算法
深入地理解这些算法,以及理解在不同的场景中如何有效地应用这些算法,对一名开发人员很重要。
因此,让我们来深入研究其中的每一个算法,研究它们是什么、它们是如何工作的以及何时使用它们。
1. 一致性哈希
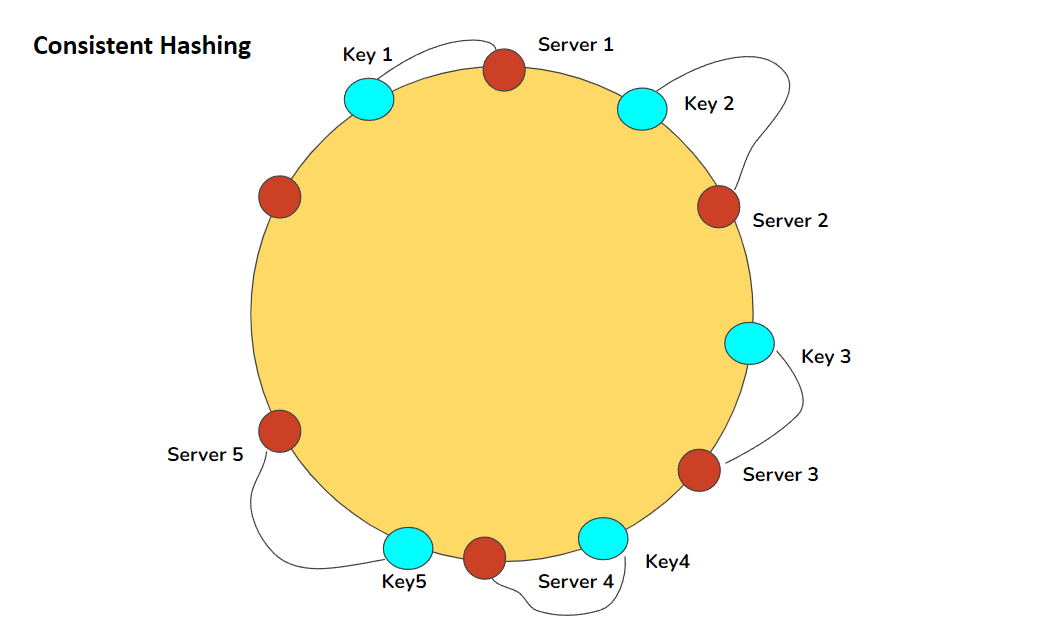
一致性哈希是分布式系统中用于在多个节点之间有效分发数据的技术。当在系统中添加或删除节点时,它可以使系统最小化在节点之间迁移的数据量。
一致性哈希背后的基本原理是使用哈希函数将每条数据映射到系统中的某个节点。每个节点都分配了一段哈希值范围,哈希值映射到该范围内的的任何数据都会被分配到该节点。
当从系统中添加或删除节点时,需要将分配给该节点的数据迁移到另一个节点,这个过程是通过使用虚拟节点的概念来实现的,并不是直接为每个物理节点分配一系列哈希值,而是为每个物理节点分配了多个虚拟节点,每个虚拟节点都被分配了一段唯一的哈希值范围,任何哈希值映射到该范围内的数据都被分配给虚拟节点相对应的物理节点上。
当从系统中添加或删除节点时,只有受影响的虚拟节点上的数据需要重新分配,并且分配给这些虚拟节点的所有数据都将被迁移到另外一个节点,这就允许系统动态高效地进行扩展,从而避免在每次添加或删除节点时需要重新分配数据。
总的来说,一致性哈希提供了一种在分布式系统中的多个节点之间分发数据的简单而有效的方法。它通常用于大型分布式系统,例如内容分发网络(CDN)和分布式数据库,用来提供高可用性和可扩展性。
2. Map reduce
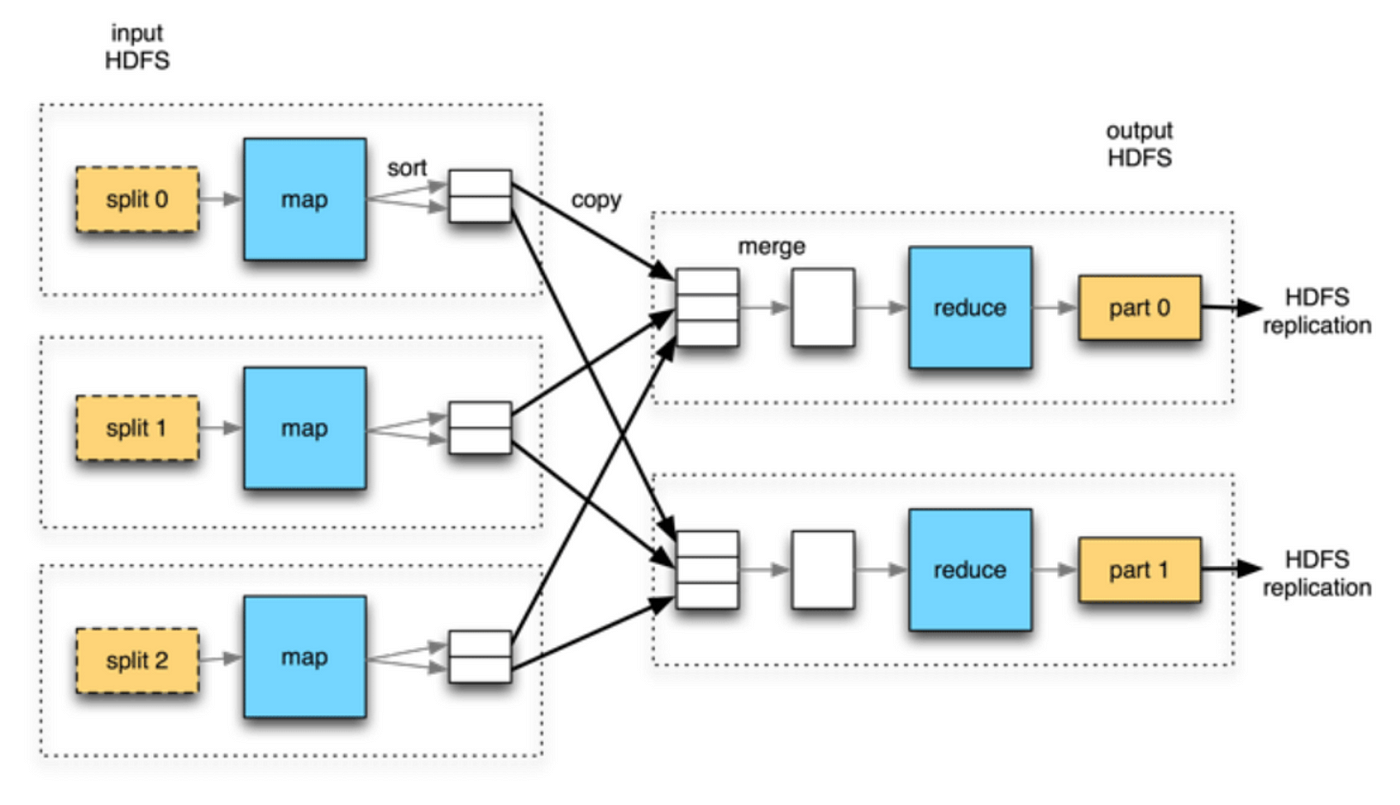
MapReduce 是一种用于在分布式系统中处理海量数据集的编程模型和框架。它的思想最初由谷歌提出,目前广泛应用于许多大数据处理系统,例如 Apache Hadoop。
MapReduce 背后的基本思想是将海量数据集切割成较小的数据块,并将这些数据块分布在集群中的多个节点上,多个节点之间并行处理数据,处理过程分为两个阶段:Map阶段和Reduce阶段。
在 Map 阶段,输入数据集由一组 Map 函数并行处理,每个 Map 函数都将一组键值对作为输入,并生成一组中间键值对作为输出,然后将这些中间键值对按键排序和分区,并发送到 Reduce 阶段进行处理。
在 Reduce 阶段,Map 阶段生成的中间键值对被一组 Reduce 函数并行处理,每个 Reduce 函数都将一个键和一组值作为输入,并生成输出一组键值对。
下面是一个示例,说明如何使用 MapReduce 计算大型文本文件中单词的出现频率:
- Map阶段:每个
Map函数读取输入文件的一个数据块并输出一组中间键值对,其中键是某个单词,值是该单词在数据块中出现的次数; - Shuffle阶段:对生成的中间键值对按键排序和分区,以便将相同单词分组到一起;
- Reduce阶段:每个
Reduce函数都将某个单词和该单词出现次数作为输入,并输出一个键值对,其中键是该单词,值是输入文件中该单词出现的总次数。
MapReduce 框架负责计算的并行处理、数据分布处理和机器故障容错,这使它能够高效可靠地处理海量数据集,即使是在普通的商用硬件集群上也是如此。
3. 分布式哈希表(DHT)
分布式哈希表(DHT)是一种分布式数据结构,可提供散列的键值存储,它常用于 P2P 网络场景,通过可扩展和容错的方式存储和检索信息。
在 DHT 中,每个参与计算的节点存储的是所有键值对的子集,并使用映射函数将键分配到某个节点,这使得某个节点仅通过查询一小部分节点就可以定位到与给定键关联的值,而且查询的通常是那些映射空间中接近给定键的所在节点的键。
DHT 提供了几个优秀的特性,例如自组织、容错、负载均衡和高效路由。DHT 通常用于 P2P 文件共享系统、内容分发网络(CDN)和分布式数据库等场景。
一种非常流行的 DHT 算法是 Chord 协议算法,它使用基于环的拓扑结构和一致性的哈希函数将数据键分配给某个节点;另一个广泛使用的 DHT 算法是 Kademlia 协议算法,它使用二叉树树状结构来定位存储给定键的节点。
4. 布隆过滤器
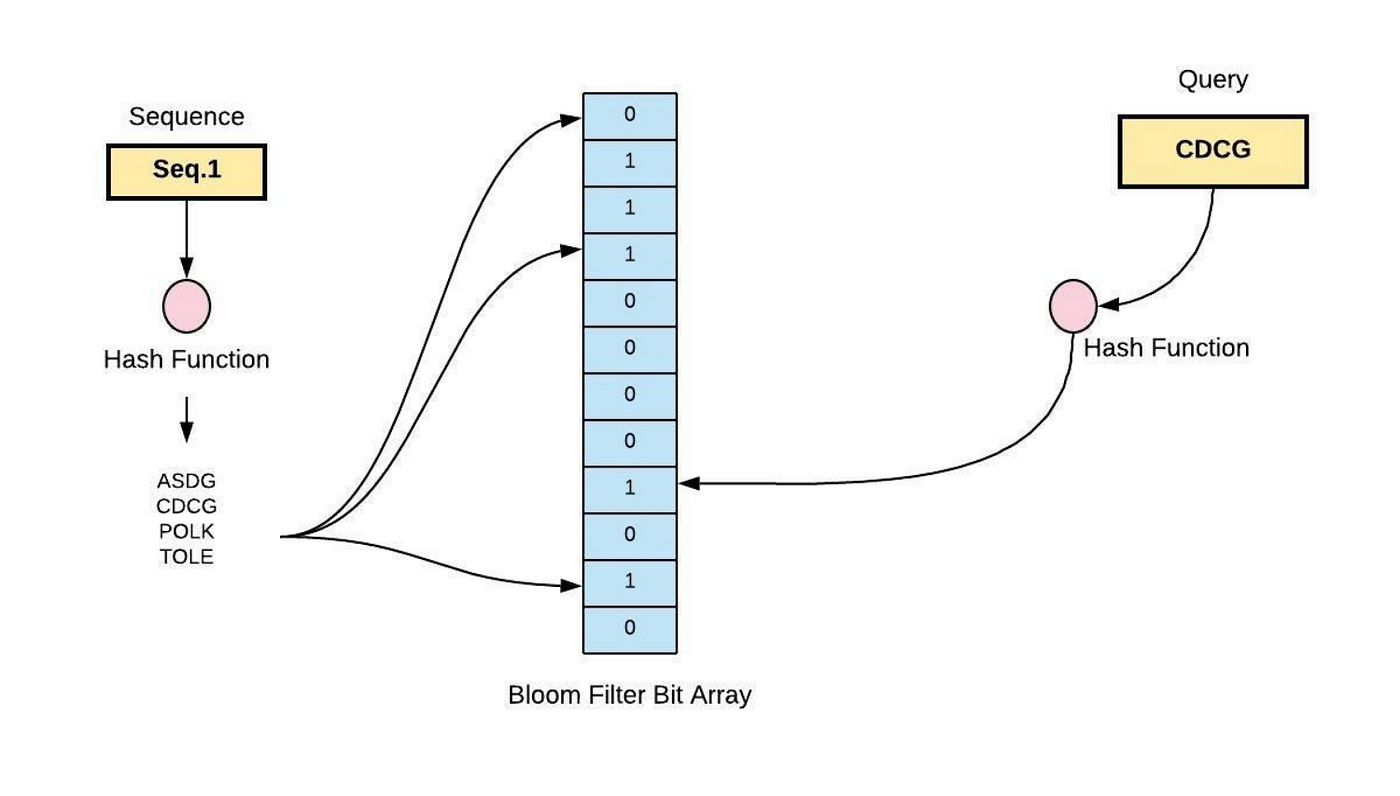
布隆过滤器是一种概率数据结构,通常用于高效的测试集合中是否存在某个元素,它是由 Burton Howard Bloom 于 1970 年提出的。布隆过滤器是一种节省存储空间的概率数据结构,用于测试元素在集合中是否存在,它使用位数组和一组哈希函数来存储和检查集合中是否存在某个元素。
将元素添加到布隆过滤器的过程首先将元素传入给一组散列函数,这些哈希函数返回位数组中的一组索引位置,然后将位数组中对应索引位置的值设置为 1。
为了检查集合中是否存在某个元素,首先对该元素应用相同的哈希函数,并在位数组中检查哈希函数结果对应的索引位置的值,如果对应索引位置的所有值都为 1,则认为该元素可能存在于集合中;但是如果对应索引位置的某个值 0,则认为该元素不存在于集合中。
由于布隆过滤器使用哈希函数来索引位数组,因此存在误报的可能性,即过滤器可能判断认为某个元素存在于集合中,而实际上它不存在;但是可以通过调整位数组的大小和使用的哈希函数的数量来控制误报出现的概率;假阴性率(即布隆过滤器无法识别集合中实际存在的元素的概率)可以做到为零。
布隆过滤器广泛应用于网络、数据库和网络缓存等各个领域,用来高效地测试集合中是否存在某个成员。
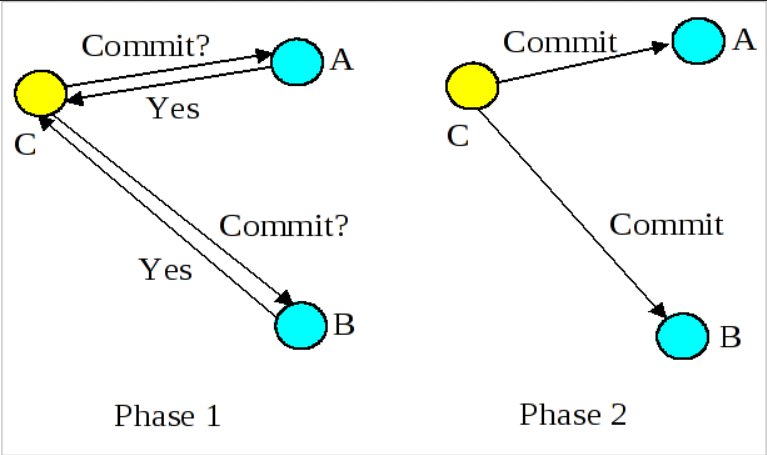
5. 两阶段提交
两阶段提交(2PC)是一种用于保证分布式系统中事务的原子性和一致性的协议,它能够保证参与事务的所有节点一起提交或回滚的思想。
两阶段提交协议分两个步骤:
- Prepare阶段:在
prepare阶段,协调者向所有参与者发送消息,要求它们准备提交事务;每个参与者都会回复一条响应消息,表明它是否做好提交事务准备,如果某个参与者还未准备就绪,它会回复一条消息,表明它无法参与事务; - Commit阶段:如果所有参与者都已经做好提交准备,协调者会向所有节点发送一条消息,要求他们提交事务,每个参与者提交事务后会向协调者发送确认消息,如果某个参与者无法提交事务,它会回滚事务并向协调者发送一条消息,表明它已回滚事务。
如果协调者收到所有参与者的确认消息,它会向所有节点发送一条消息,表明事务已提交;如果协调器收到某个参与者的回滚消息,它会向所有节点发送一条消息,指示事务已回滚。
两阶段提交协议能够确保分布式系统中的所有节点事务结果是一致的,即使出现故障也是如此;然而它也有一些缺点,包括延迟较高和死锁的可能性,此外它需要一个协调者节点,这可能引起单点故障。
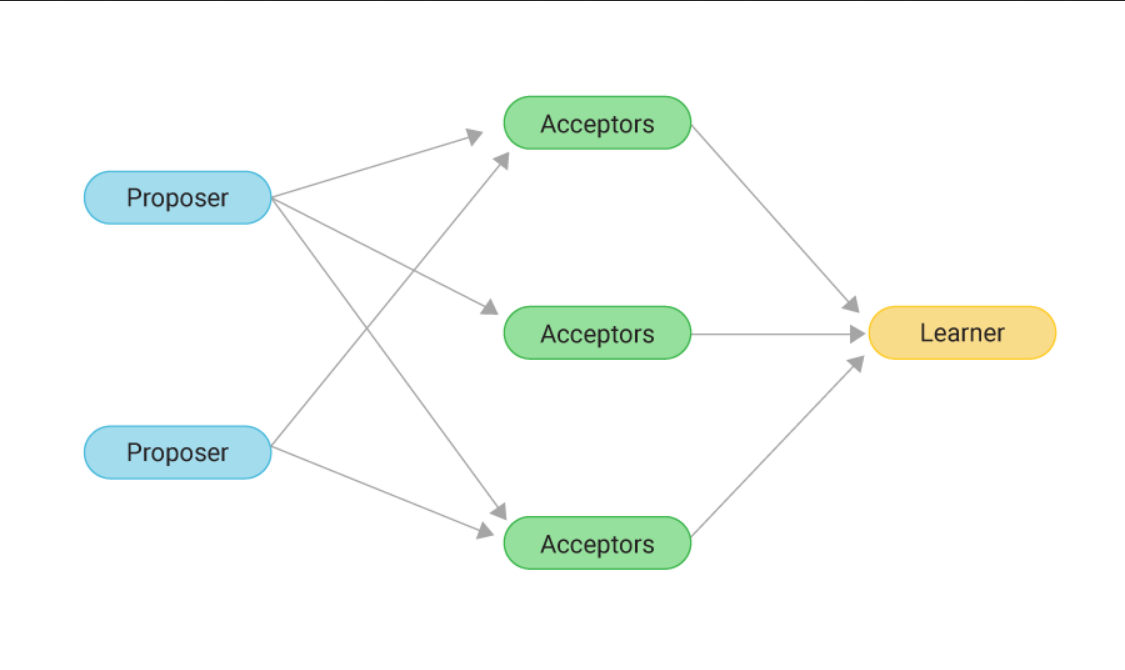
6. Paxos
Paxos 是一种分布式共识算法,即使在某个节点出现故障的情况下,也允许一组节点就某个结果值达成一致。它是由 Leslie Lamport 于 1998 年提出,现已成为分布式系统的基本算法。
Paxos 算法旨在处理各种故障场景,包括消息丢失、重复、重排序和节点故障等等。该算法分两个阶段进行:prepare阶段和accept阶段。在prepare阶段,一个节点向所有其他节点发送一个 prepare 消息,要求他们确保不接受任何数值小于一定值的提议。
一旦大多数节点响应提案消息,节点就可以进入accept阶段,在accept阶段,节点向所有其他节点发送 accept 消息,提出某个值,如果大多数节点响应消息内容,则该值被视为已接受。
Paxos 是一种复杂的算法,它有多种变体和优化,例如 Multi-Paxos、Fast Paxos 等;这些变体的目的是减少交换的消息数量,优化算法的延迟,并减少需要参与共识的节点数量。Paxos 被广泛应用于分布式数据库、分布式文件系统等需要高度容错性的分布式系统中。
7. Raft
Raft 是一种共识算法,旨在确保分布式系统的容错性。它负责维护一个复制的日志,该日志存储跨集群中多个节点的一系列变更状态。Raft 通过选举一个领导者来达成共识,领导者协调各个节点之间的通信,并确保日志在整个集群中的状态是一致的。
Raft 算法由三个主要部分组成:领导者选举、日志复制和安全性。在领导者选举阶段,集群中的节点使用随机超时机制选举领导者。
领导者通过接收从客户端发送的数据变更并将它们复制到集群中的其他从节点来协调日志复制,从节点还可以向领导者请求日志条目以确保整个集群的一致性。
Raft 的安全组件确保共识算法对系统故障具备容错性,并确保日志在整个集群中保持一致;Raft 算法确保在任何给定时间只有一个领导者节点并通过在集群中强制执行严格的日志条目排序来实现安全性。
Raft 广泛用于分布式系统,以提供容错性和高可用性。它通常用于需要保证强一致性的系统,例如分布式数据库和分布式键值存储。
8. Gossip
Gossip 协议是分布式系统中快速有效地传播信息的点对点通信协议。它是一种概率协议,允许节点以去中心化的方式与相邻节点交换状态信息数据。该协议的名称来源于传播谣言或八卦等信息的方式。
在 Gossip 协议中,某个节点随机选择一组其他节点来与之交换信息。当一个节点从另一个节点接收到信息时,它将将该信息转发给其相邻的其他节点,然后该过程会继续进行。随着时间的推移,当信息从一个节点传播到另一个节点时,整个网络中节点就全部能够识别到这些信息。
Gossip 协议的主要优点之一是它的容错性。由于该协议依赖于概率通信而不是中心化节点,因此即使某些节点出现故障或退出网络,它也可以继续运行。这使它成为分布式系统中的一个有用工具,能够解决分布式系统中可靠性这个关键问题。
Gossip 协议已用于各种应用程序,包括分布式数据库、P2P 文件共享网络和大规模传感器网络。它们特别适合需要在大量节点之间快速有效地传播信息的应用程序。
9. Chrod
Chord 是一种分布式哈希表 (DHT) 协议,用于去中心化 (P2P) 系统。它提供了一种在给定标识符的情况下在 P2P 网络中快速定位某个节点(或一组节点)的方法。Chord 允许 P2P 系统扩展到大量节点,同时能够保持较低系统开销。
在 Chord 网络中,每个节点都分配有一个唯一的标识符,可以是任意 m 位数字。所有节点排列成一个环,节点之间根据它们的标识符按顺时针方向排序,每个节点负责存储一组键,键可以是 0 到 2^m-1 范围内的任意值。
为了在网络中找到一个键,某个节点首先计算这个键的哈希值,然后定位其标识符是该哈希值的顺时针第一个后继者节点;如果后继节点上没有所需的键,它将请求继续转发给它的后继节点,依此类推,直到找到这个键。这个过程被称为 finger lookup,它通常需要发送对数级别的消息才能找到所需的节点。
为了保持网络的一致性,Chord 使用一种称为 finger table 的协议,它负责存储网络中其他节点的信息。每个节点都维护一个 finger table,其中包含环中距离越来越远的后继者节点的标识符;这使得某个节点有效地定位网络中的其他节点,而无需维护所有节点的完整列表。
Chord 还能够确保在网络中添加或删除节点时保持一致性。当网络中添加一个节点时,它会通知它的直接后继者,后者相应地更新它的 finger table;当在网络中删除某个节点时,这个节点上的键被迁移到它的后继节点,后继节点更新它的 finger table 以记录节点被删除。
总的来说,Chord 提供了一种高效且可扩展的方式,使用简单且去中心化协议在 P2P 网络中定位某个节点。
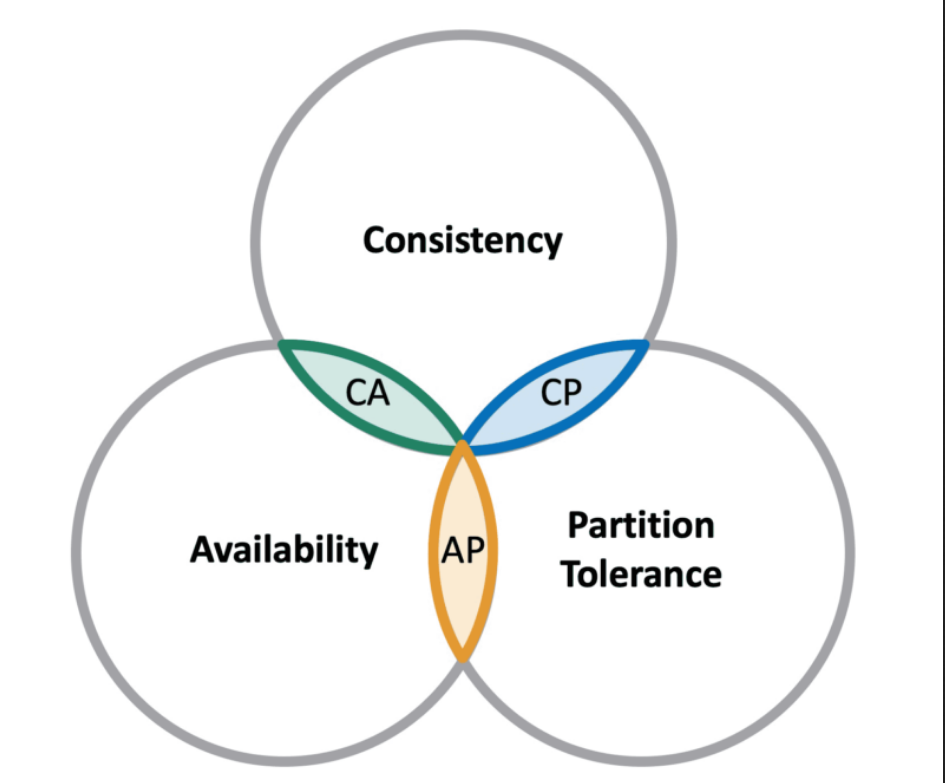
10. CAP 理论
CAP 定理,也称为布鲁尔定理,是分布式系统中的一个基本概念,它指出分布式系统不可能同时保证以下三个特性:
- 一致性:每次读取都会返回最新写入的新数据或错误;
- 可用性:每次请求都会接收到一个响应结果,但不保证它返回的是最新版本的信息;
- 分区容错性:即使发生网络分区,系统也能继续运行并提供一致且可用的服务。
换句话说,分布式系统只能满足上述三个特性中的两个;这个定理意味着在出现网络分区的情况下,分布式系统必须在一致性和可用性之间做出选择。
例如在分区系统中,如果一个节点无法与另一个节点通信,则它必须返回错误或返回可能已经过时的响应结果。
CAP 定理对设计分布式系统具有重要意义,因为它要求开发人员在一致性、可用性和分区容错性之间进行权衡。
总结
这就是我们可以在 2023 年学习的基本系统设计数据结构、算法和协议。总而言之,系统设计是软件工程师的一项基本技能,尤其是那些从事大规模分布式系统的工程师。
这十种算法、数据结构和协议为解决复杂问题而生,并为构建可扩展、可靠的系统提供了坚实的基础。通过了解这些算法并在使用中做出权衡取舍,我们可以在设计和构建系统时做出明智的选择。
此外,学习这些算法可以帮助我们准备系统设计面试并提高大家解决问题的能力。但是请务必注意,这些算法只是一个起点,我们应该随着技术的发展不断学习和适应新的技术。