/** * Creates a new, empty map with the default initial table size (16). * 创建空的 map,默认初始容量 16 */ publicConcurrentHashMap() {
}
/** * Creates a new, empty map with an initial table size * accommodating the specified number of elements without the need * to dynamically resize. * * @param initialCapacity The implementation performs internal * sizing to accommodate this many elements. * @throws IllegalArgumentException if the initial capacity of * elements is negative */ publicConcurrentHashMap(int initialCapacity) { if (initialCapacity < 0) thrownewIllegalArgumentException(); intcap= ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY : tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1)); this.sizeCtl = cap; }
ConcurrentHashMap 类的构造方法还是有些特殊的:
在构造方法内部并没有进行 table 的初始化操作,初始化的过程放到了 put 方法中来完成,后面我们还会讲到;
/** * Spreads (XORs) higher bits of hash to lower and also forces top * bit to 0. Because the table uses power-of-two masking, sets of * hashes that vary only in bits above the current mask will * always collide. (Among known examples are sets of Float keys * holding consecutive whole numbers in small tables.) So we * apply a transform that spreads the impact of higher bits * downward. There is a tradeoff between speed, utility, and * quality of bit-spreading. Because many common sets of hashes * are already reasonably distributed (so don't benefit from * spreading), and because we use trees to handle large sets of * collisions in bins, we just XOR some shifted bits in the * cheapest possible way to reduce systematic lossage, as well as * to incorporate impact of the highest bits that would otherwise * never be used in index calculations because of table bounds. */ staticfinalintspread(int h) { return (h ^ (h >>> 16)) & HASH_BITS; }
/** * Maps the specified key to the specified value in this table. * Neither the key nor the value can be null. * * <p>The value can be retrieved by calling the {@code get} method * with a key that is equal to the original key. * * @param key key with which the specified value is to be associated * @param value value to be associated with the specified key * @return the previous value associated with {@code key}, or * {@code null} if there was no mapping for {@code key} * @throws NullPointerException if the specified key or value is null */ public V put(K key, V value) { return putVal(key, value, false); }
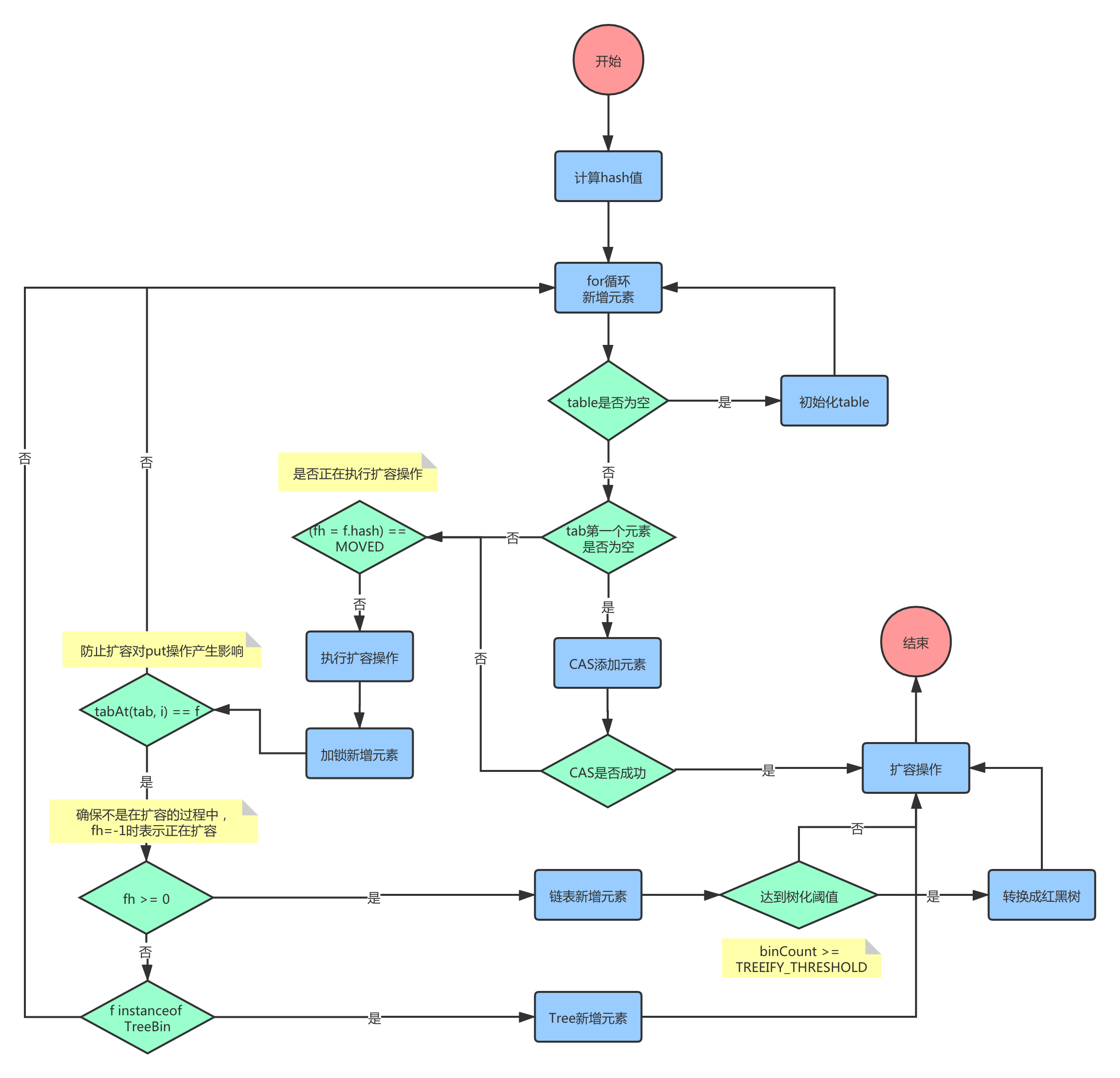
/** Implementation for put and putIfAbsent */ final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) { thrownewNullPointerException(); } // 计算hash值 inthash= spread(key.hashCode()); intbinCount=0; for (Node<K,V>[] tab = table; ;) { Node<K,V> f; int n; int i; int fh; if (tab == null || (n = tab.length) == 0) { // 初始化tab tab = initTable(); // 找到tab中的第一个元素 } elseif ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // 如果第一个元素为空,执行cas操作,添加元素 if (casTabAt(tab, i, null, newNode<K,V>(hash, key, value, null))) { // 当向一个空bin添加元素时使用无锁的CAS break; // no lock when adding to empty bin } } elseif ((fh = f.hash) == MOVED) { // 处理map正在扩容中的场景 tab = helpTransfer(tab, f); } else { VoldVal=null; // 加锁执行添加元素操作 // 锁f是通过tabAt方法获取的 // 也就是说,当发生hash碰撞时,会以链表的头结点作为锁 synchronized (f) { // 这个检查的原因在于: // tab引用的是成员变量table,table在发生了rehash之后,原来index上的Node可能会变 // 这里就是为了确保在put的过程中,没有收到rehash的影响,指定index上的Node仍然是f // 如果不是f,那这个锁就没有意义了 if (tabAt(tab, i) == f) { // 确保put没有发生在扩容的过程中,fh=-1时表示正在扩容 if (fh >= 0) { binCount = 1; for (Node<K,V> e = f; ; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) { e.val = value; } break; } Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = newNode<K,V>(hash, key, value, null); break; } } } // 如果是红黑树,执行红黑树插入操作 elseif (f instanceof TreeBin) { Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) { p.val = value; } } } } } // 如果超过设定阈值,转换成红黑树 if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD) { treeifyBin(tab, i); } if (oldVal != null) { return oldVal; } break; } } } addCount(1L, binCount); returnnull; }
/** * Returns the value to which the specified key is mapped, * or {@code null} if this map contains no mapping for the key. * * <p>More formally, if this map contains a mapping from a key * {@code k} to a value {@code v} such that {@code key.equals(k)}, * then this method returns {@code v}; otherwise it returns * {@code null}. (There can be at most one such mapping.) * * @throws NullPointerException if the specified key is null */ public V get(Object key) { Node<K, V>[] tab; Node<K, V> e; Node<K, V> p; int n; int eh; K ek; inth= spread(key.hashCode()); tab = table; n = tab.length; e = tabAt(tab, (n - 1) & h); if (tab != null && n > 0 && e != null) { eh = e.hash; if (eh == h) { ek = e.key; if (ek == key || (ek != null && key.equals(ek))) { return e.val; } } elseif (eh < 0) { p = e.find(h, key); return p != null ? p.val : null; } e = e.next; while (e != null) { ek = e.key; if (e.hash == h && (ek == key || (ek != null && key.equals(ek)))) { return e.val; } e = e.next; } } returnnull; }
通过上面的源码,我们可以看到,在 ConcurrentHashMap 类的 get 方法并没有任何加锁操作,那是如何来保证线程安全的。
/** * Key-value entry. This class is never exported out as a * user-mutable Map.Entry (i.e., one supporting setValue; see * MapEntry below), but can be used for read-only traversals used * in bulk tasks. Subclasses of Node with a negative hash field * are special, and contain null keys and values (but are never * exported). Otherwise, keys and vals are never null. */ staticclassNode<K,V> implementsMap.Entry<K,V> { finalint hash; final K key; volatile V val; volatile Node<K,V> next;